≡
Продолжая серию постов про поиск и обработку языка, хотелось бы провести небольшую работу над ошибками. Предыдущий пост про извлечение фактов по всей видимости оказался крепким орешком для неподготовленного читателя. Несмотря на то, что я потратил на него в 2 раза больше времени, я получил в 4 раза меньше тематического фидбека.
Вообще когда я затевал эту идею, я боялся, что посты покажутся слишком дилетантскими, набигут выколобые интеллектуалы и, размахивая теоремами высшей дискретной геометрии и зачеткой за второй курс факультета математики и матанализов, разнесут мою мотивацию продолжать писать в пух и прах. Однако сейчас мне становится очевидно, что бояться нужно противоположного — что посты будут непонятными широкому кругу читателей.
Потому теперь я снова стараюсь вернуться к популярному стилю изложения, целью которого является заинтересовать, а не объяснить в подробностях. Оставшихся же 0 человек, которым будут интересны подробности, я приглашаю в комментарии или на рюмочку чая. Попробуем такую схему.
Всегда сложно выбирать тему для поста, это как назвать все слова, которые знаешь. Даже если ваш словарный запас — тысячи, на втором десятке вы уже затупите (намекаю, что стоит подсказывать мне новые интересующие вас темы). Сегодня хотелось бы затронуть область, напрямую не связанную с NLP, однако идущую с ней бок-о-бок: рекомендательные системы.
С рекомендательными системами нам приходится встречаться всё чаще и чаще по банальной причине: сферические моркетологи каждый год проводят сферические исследования, в которых огромными сферическими процентами намекают как увеличивается количество покупок (aka конверсия) в вашем интернет-магазине, если под каждым товаром висит блок «похожие товары», или «возможно вы захотите приобрести», или «с данным товаром покупают еще».
Ну а если без шуток, то это действительно так.
 Всем известный last.fm вырос благодаря рекомендательным алгоритмам
Всем известный last.fm вырос благодаря рекомендательным алгоритмам
Потому из всей нашей сферы наверное именно рекомендательные системы имеют самую большую популярность, их полезность легче всего доказывается вашему начальству с помощью красивых графиков, в отличии от всех остальных систем. На основе одних только рекомендательных алгоритмов строят целые проекты, тот же LastFM или Имхонет, Prismatic или наш отечественный Surfingbird, а Яндекс недавно решил снова всех побить и выпустил «рекомендации для всех и обо всём» под названием Яндекс.Атом.
Рекомендательные системы — это комплексы алгоритмов, которые пытаются предсказать какие объекты (товары) будут интересны пользователю, имея определенные данные о его профиле (интересах, истории просмотров, оценок). Традиционно рекомендательные системы разделяют на четыре типа:
Примеры условий: Юзеру N, со схожими с вашими оценками, понравился этот фильм, вероятно вам он тоже понравится. Фильм M похож на фильмы, которые вы уже высоко оценили, возможно он вам тоже понравится.
Примеры сервисов: Имхонет, last.fm.
Плюсы: Теоретически высокая точность.
Минусы: Высокий порог входа: не зная ничего об интересах юзера, рекомендации практически бесполезны, многие юзеры будут просто сразу уходить.
Примеры условий: Начиная от простых: «Книги того же жанра или автора», «Вещи того же производителя», до «Вам нравятся комедии с Джимом Керри, вот вам подборка комедий с ним».
Примеры сервисов: Prismatic, Surfingbird.
Плюсы: Можно делать рекомендации даже незнакомым юзерам, тем самым вовлекая их в сервис. Возможность рекомендовать те объекты, которые еще не были никем оценены.
Минусы: Точность сильно падает, время разработки немного возрастает.
Примеры условий: К этому плееру вам возможно пригодятся наушники. Вы купили отличную камеру, вот вам 10% скидки на сумку для нее.
Примеры сервисов: Крупные интернет-магазины, в том числе Российские (точно видел у связного).
Плюсы: Возможность исключить любимую ситуацию всех систем рекомендации: «Вы только что купили квартиру в Москве? Вероятно вот эти 5 квартир в Москве вам тоже пригодятся!». Возможность регулировать ситуации типа «макбук 2007 года оценили на 5.0, а макбук 2014 на 4.9, значит макбук 2007 года лучше».
Минусы: Высокая сложность разработки и сбора данных.
Примеры условий: Ограничены только воображением создателей.
Примеры сервисов: кроме Netflix не удалось нагуглить примеров.
Плюсы: Самая высокая точность, у Netflix погрешность примерно 0.86 балла для 5-балльной шкалы оценок. Хотя, конечно, всё зависит от реализации.
Минусы: Самая высокая сложность разработки.
 Пример коллаборативной фильтрации на имхонете
Пример коллаборативной фильтрации на имхонете
Разберем немного подробней каждый из типов систем. Коллаборативная фильтрация всегда предполагает то, что у нас есть данные о пользователях и объектах, которые они оценили (в том числе о текущем пользователе). Тогда фильтрация разделяется на два типа: user-based и item-based.
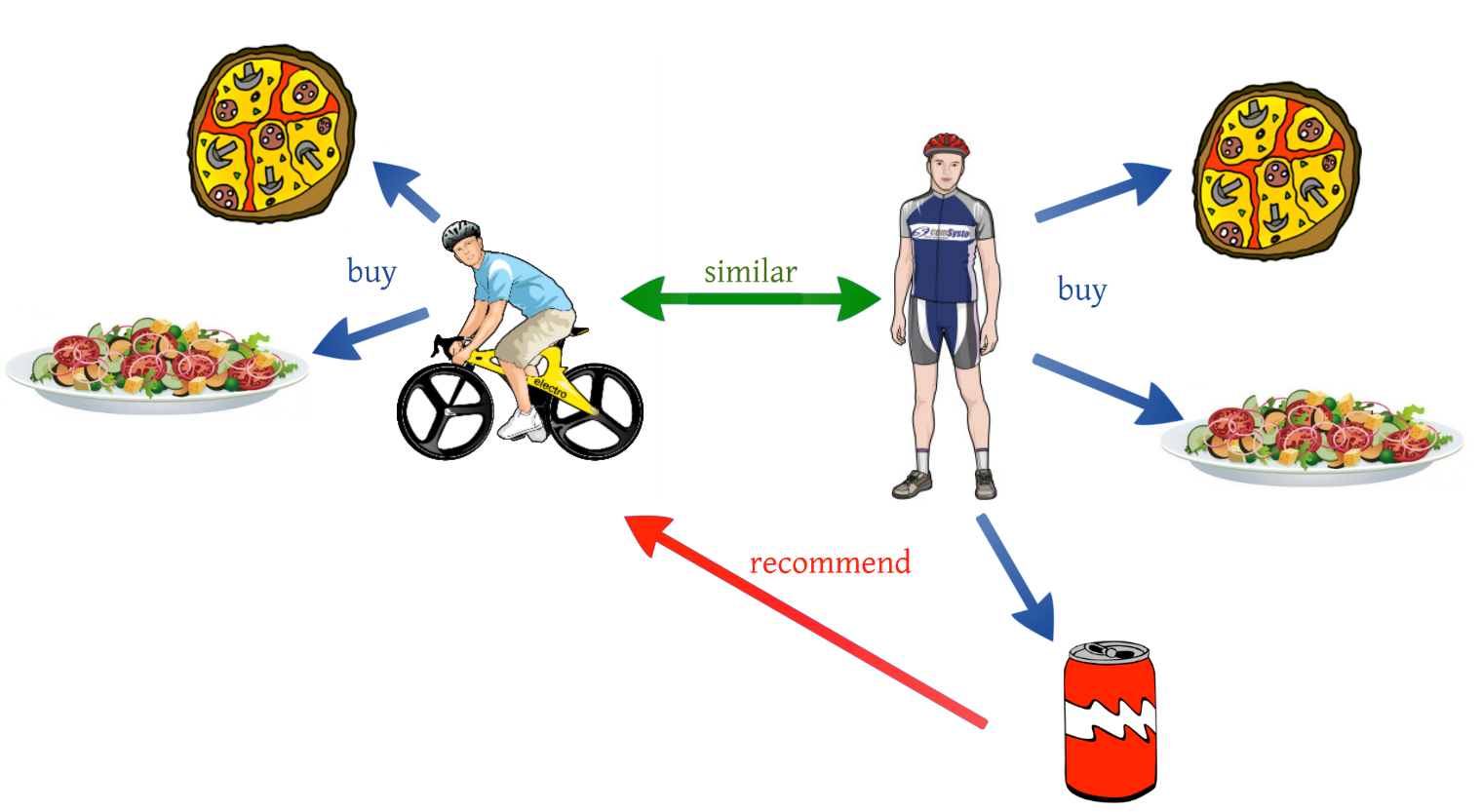
В случае user-based рекомендации строятся по принципу: «найти пользователей, похожих на меня, и посмотреть нравится ли им данный объект». Например: «Пользователи Алеша и Борис любят митболы, латте и стартапы, а пользователь Валера любит митболы и латте, значит скорее всему ему нужно начинать стартап».
В случае item-based логика рекомендаций поворачиваются другой стороной: «найти объекты, похожие на заданный, и посмотреть как я их оценивал ранее». Например: «Понравится ли Валере делать стартапы? Валера любит латте и митболы, значит скорее всего ему понравятся стартапы».
По ссылке выше user- и item-based системы описаны достаточно хорошим и простым языком, в благодарность автору отправляю всех читателей, заинтересованных в подробностях, именно туда. Коллаборативная фильтрация в теории — штука достаточно простая: найти юзеров, оценивших данный объект, а затем посчитать коэффициент корреляции векторов их оценок всем объектам в базе. Взять, например, k юзеров с самыми высокими коэффициентами корреляции и посмотреть как они чаще всего оценивали данный объект (типичный алгоритм k-ближайших соседей). Для увеличения точности не забыть разделить каждую оценку на среднюю оценку юзера (чтобы сгладить влияние «хейтеров» и «мне нравится всё» юзеров).
Здесь я хотел упомянуть еще метод SVD (Сингулярное Разложение Векторов — какое название-то!), который на данный момент является передовым в области коллаборативной фильтрации, но статья и так получается длинной, можете попросить написать продолжение.
Content-based системы опираются на знания об объектах, совершенно игнорируя как там эти объекты оценивали другие пользователи. В качестве знаний об объекте выступают любые его свойства, которые мы можем добыть: жанр, производитель, автор, страна, в общем всё, что вы сможете добыть в вашей области. Только увлекаться тоже не стоит, например, производитель процессора не часто является релевантным свойством при выборе смартфона.
В последнее время именно content-based рекомендации становятся самыми популярными, потому что никто из пользователей не хочет тратить время на «обучение» системы своим предпочтениями, а никто из создаталей систем не хочет терять кучу пользователей сразу после регистрации. Отсюда и имеем кучу жалоб и шуток про то, что «я купил джинсы на ибее и он теперь мне постоянно джинсы предлагает» или «зашел на сайт с обручальными кольцами, теперь Яндекс.Директ везде предлагает купить их».
Content-based системы стали настолько популярны, что всех начинает тошнить от их глупых и неуместных рекомендаций. Так что думайте, перед тем как пилить очередную контент-ориентированную систему, не будет ли она раздражать ваших пользователей как 90% существующих. Или может у вас есть время и мозги, чтобы попробовать расширить ее дополнительными условиями и двинуться в сторону knowledge-based.
Зато эти системы опираются на уже известные нам знания про TF-IDF и схожесть документов и практически ничего нового при их написании изучать не придется. Та же обработка языка, та же классификация (кстати хотел написать про фильтрацию спама, но пока думаю не банально ли это, если хоть кому-то это интересно, опишитесь), всё это понятно, известно и достаточно просто: нашел похожие документы и выдал на странице.
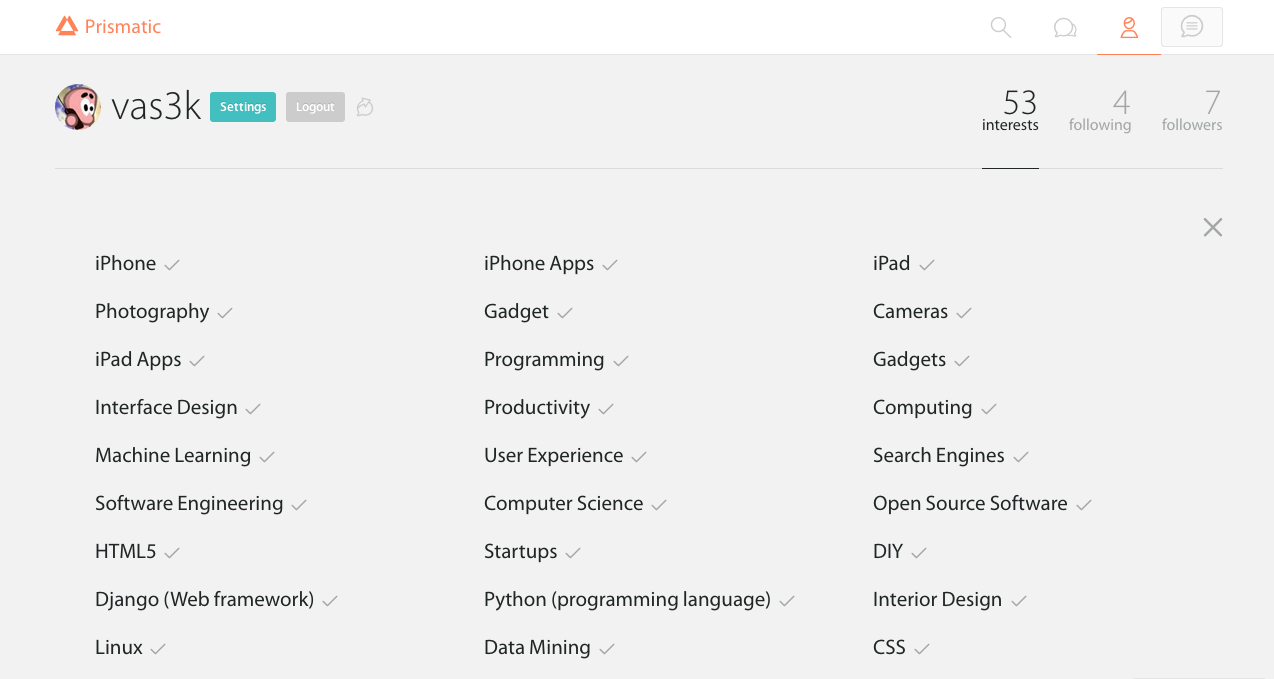 Prismatic — типичная content-based система
Prismatic — типичная content-based система
Рекомендательные системы основанные на знаниях так же не опираются на оценки других юзеров, а смотрят только на профиль пользователя и товара. Дальнейшие пути всегда различны. Объединяет их то, что каждый путь подразумевает наличие знаний о какой-то предметной области. Либо о пользователях, либо о товарах, либо еще о чем-либо, что может помочь ранжированию.
Case-based подход подразумевает наличие дополнительной сущности: требований пользователя (user requirements). Требования могут выглядеть как: «современная зеркальная камера с минимум 32 точками автофокуса и ценой до $2000» и могут задаваться путем выбора нужных чекбоксов. Задача подхода заключается просто в том, чтобы найти рекомендованные товары, согласно требованиям.
Demographic-based учитывает свойства непосредственно пользователя. Насколько он обеспечен, где живет, сколько зарабатывает, и.т.д.
 Шкала на имхонете. Правда по качеству его рекомендаций мне кажется она сделана только для красоты.
Шкала на имхонете. Правда по качеству его рекомендаций мне кажется она сделана только для красоты.
Utility-based рассчитывает относительную полезность каждого товара для пользователя. Если пользователь гик, скорее всего и фотоаппарат он выберет с наибольшим количеством функций. Если пользователь купил фотоаппарат, скорее всего он за объективами для него придет.
Critique-based имеют дополнительный интерфейс для «критики». Например две оси, по которым пользователь будет задавать «хочу дороже, но с большим количеством мегапикселей», а система пытаться подстроиться под запрос.
Whatever-you-want-based как можно заметить, практически все подвиды knowledge-based систем зависят исключительно от воображения их авторов. В каждом конкретном случае можно выдумывать свои области знаний и ранжировать по ним, достигая максимальных результатов. Всё зависит только от вас.
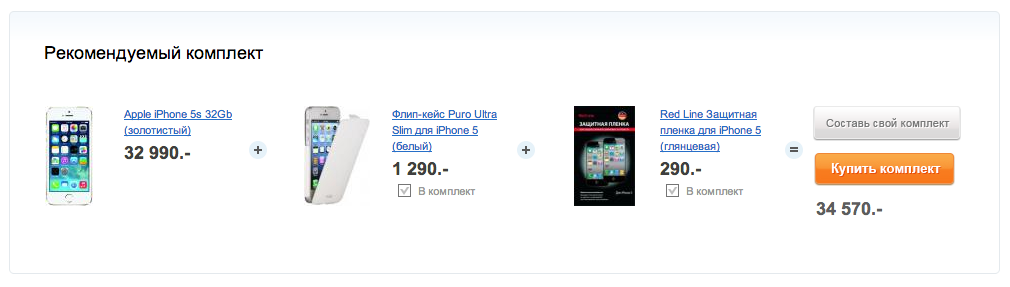 Пример основанных на знаниях рекомендаций у Связного
Пример основанных на знаниях рекомендаций у Связного
В гибридных рекомендательных системах уже, как говорится у классика, «пацаны ебашатся по хардкору». Все «настоящие» рекомендательные системы, как и поисковые системы, почти всегда — гибриды. Их разработчики применяют машинное обучение чтобы выделять самые релевантные для пользователя алгоритмы, применяют методы оптимизации для поиска наилучших коэффициентов, в общем развлекаются как хотят. Единого алгоритма построения гибридных систем нет, к ним просто приходят все, кто попробует вышеперечисленные.
Вот вроде и всё небольшое введение. Надеюсь, хотя бы 5% дочитало досюда, за что им спасибо. По ходу изложения я достаточно часто просил всех отписываться о том, что вам было бы интересно, а что нет. Это поможет мне сориентироваться при выборе тем в дальнейшем. Вполне вероятно, что я могу считать какую-то интересную тему попросту «очевидной» (как ваш препод по матану считал очевидной 4-этажную формулу на доске), а кому-то она будет интересна. Так же пока у меня читателей не очень много, приятно будет видеть любые даже банальные благодарности, буду расценивать их как «лайки» и дополнительную мотивацию на следующей неделе снова тратить пол дня на новый пост.

Я уже даже думал завести на кинопоиске несколько аккаунтов для разных жанров, а то эта их рекомендательная система, предположительно, усреднила мои оценки и теперь выдаёт чухню. Я жираф? Эта проблема коллаборативного варианта как-нибудь решается? Я имею ввиду, что киберпанк_фильм_1 мне понравился, понравилась и какая-нибудь глупая_комедия_1, а другие ценители_киберпанка её оценили плохо, значит другие их фавориты киберпанка мне не понравятся. лолштоянаписал
ReDetection, > Эта проблема коллаборативного варианта как-нибудь решается? Теоретически это решается с помощью <a href="http://ru.wikipedia.org/wiki/Латентное_размещение_Дирихле">смесей интересов</a>. Можно попробовать представить пользователя не как единого персонажа, а как персонажа с различными интересами, смешанными в различных пропорциях. А вообще: больше данных — точнее система. Даже самый тупой алгоритм при наличии достаточного количества данных определит тебя в класс "фанат киберпанка и комедии такой-то", но это скорее мечты, чем реальность.
Спасибо, полезный пост! >Вы - бот? Почему-то мне каждый раз хочется заполнить это поле словом "нет". Наверное, я бот :(
артур, то, что ты описал, и есть типичная content-based система с несколькими критериями. Подходит для фильмов, но например совершенно бесполезна на квартирах. > на основе подробного списка создателей знакомых мне альбомов А чем создатель альбома отличается от исполнителя? Серьезно, я просто не в курсе.
vas3k, в фильме кроме режиссера и исполнителя главной роли есть сценарист, композитор, оператор, монтажер и прочие замечательные люди, у которых есть любимые приемы и узнаваемые фишки. В музыке: в одной группе 3-4 участника, плюс сессионные/приглашенные музыканты, плюс продюссер, плюс инженеры (иногда известные). Основные музыканты после распада группы продолжают делать сольники в примерно том же стиле и часто пересекаются с коллегами и делают сайд-проекты. Сессионники часто известные чуваки, у которых есть свои альбомы, а также куча собственно участий в альбомах других музыкантов где-нибудь на заднем плане (стиль музыки и специфические особенности при этом могут сохраняться, а жанр нет). А еще у участников группы могут быть родственники, которые тоже делают музыку не без влияния друг на друга, пусть и в разных жанрах. Работа продюссера также накладывает отпечаток на стиль исполнения команды, при том, что продюссер часто сам бывший или действующий музыкант со своим подходом к звуку и любимыми фишками, переходящими с диска на диск. Плюс есть издатели, которые специализируются на определенных жанрах. Плюс есть музыканты, которые издают себя и других самостоятельно. И все это так или иначе пересекается между собой, хоть и не напрямую. Но это, по-моему, пиздец какая сложная сеть получается. Если брать попсу, то даже там, при общей одинаковости самих исполнителей, за ними всегда стоит продюссер, авторы музыки и авторы песен, которые тоже работают в определенных стилях. То есть можно связать песню с жанром и автором текста/музыки, и выдавать песни других исполнителей песен этих же авторов. Это будет точнее, чем просто сравнение по общим жанрам.
артур, понял, тебе нужен илитарный сервис для интеллектуалов, разбирающихся в области. Похвально, возможно кто-то даже такой напишет когда-нибудь, всё это ложится на описанные в посте концепции. Все же существующие рекомендательные сервисы опираются на общую массу, которая, как известно, практически не способна выражать информационную потребность сложнее, чем "ржака на вечер" (в случае кино) или "чтоб норм качало" (в случае музыки). Именно такие простые рекомендательные сервисы востребованы, а всё остальное будет казаться переусложненным и неудобным. Хотя да, оно будет полезно 1,5 гикам. Если не скатываться в обсуждение среднего коэффициента интеллекта этой массы, местами её можно понять. Если я, например, смогу отличить режиссерский стиль Дэфида Финчера от Зака Снайдера, или узнать оператора Майкла Бея, то в той же опере или мюзиклах я совсем не разбираюсь, для меня это просто интересный опыт. Всегда нужно понимать, что общая масса смотрит кино и слушает музыку так же, как я хожу в театр, например. Мне интересно и забавно, но я ничего не понимаю «внутри». Даже если брать попсу, то без подписи внизу телекрана «стихи Валерия Меладзе, исполняет группа Корни» никто никогда не угадает этого. А стиль продюсера уж тем более не будет заметен. > То есть можно связать песню с жанром и автором текста/музыки, и выдавать песни других исполнителей песен этих же авторов. Это будет точнее, чем просто сравнение по общим жанрам. Две главные меры оценки поисковых систем — точность и полнота. И ты должен понимать, что лучшее качество у тех, кто находится посередине. Самая точная система рекомендации — это которая вернет 0 результатов и скажет "никто 100% не похож на этот трек" и будет права. Это самый точный ответ, но абсолютно бесполезный для пользователя. Если сможешь придумать как написать систему, которая будет полезна, и учитывать все эти внутренние факторы — можешь озолотиться. И здесь программировать уметь не надо, надо уметь в логику, это здесь самое сложное. Написать обычно проще, чем придумать :)
vas3k, само собой, ты прав: тут еще массу не до конца охватили, какие гики. Но ты меня немного не понял. Пользователи — тупые идиоты. Они просто платят деньги и хотят пребывать в эйфории от использования фронт-энда. Они не должны задумываться о том, как эта машина работает и машина ли это вообще, им надо получить желаемое как можно быстрее и проще. А вот со стороны создателя продукта должны быть те, кто стремится сделать систему, при которой желания юзеров угадываются с нужной им точностью вне зависимости от конкретности описания. Потому что теперешнее соотношение "точность/охват" и реализация на уровне пошаговых опросников это очень низкий уровень. Похоже, я описываю самообучаемый ИИ. Слишком сложно для очередного стартапа.
артур, в той музыке, которую слушаю я, на last.fm в «похожих исполнителях» хоть один-два сайд-проекта да найдутся, а если его открыть, в «похожих» будут остальные. Вот, например, открываем Isis (думаю, Аарона Тёрнера ты знаешь, хотя бы кто такой) и там Old Man Gloom (ну ещё хоть как-то сладж), а уже через него попадаем к остальным его группам с бесчисленным эмбиент/дрон/и т.п. реинтерпретациями и вариациями того, что исполняли Isis, интересные только настоящим фанатам, которые готовы зайти так глубоко. Т.е. система работает верно — музыка хоть и от тех же авторов, и даже с теми же мелодиями, но вряд ли она мне подойдёт, если я хочу больше ритмичного жужжания от бородатых парней с грифами до потолка. А вот у гайбов все трое стоящих сайд-проектов сразу же идут, потому что это действительно та музыка, которую стоит слушать, если тебе нравятся гайбы. Сайд-проекты создаются для того, чтобы выразить что-то, что не вписывается в концепцию существующих, и это необязательно «похожая музыка». Иногда даже берут и просто переименовывают группу, продолжая исполнять «то же самое, но уже не то». Пример: Halou → Stripmall Architecture, я далеко не сразу понял, нахера они это сделали, ведь 1 в 1 же, но большинству моих друзей, которым нравится первое, не нравится второе; видимо, я чего-то не понимаю. А гики типа нас с тобой всё равно страдают ОКР и пока лично не проверят гуглом, что больше музыки от любимых нами людей не существует, всё равно никакой рекомендательной системе не поверят. Так что идея воистину pet project для одержимых. Слава Богу, что я не такой и после отправки этого комментария пойду дальше зарабатывать деньги, но кому-то может повезти гораздо меньше :(
Не дали закончить. …то есть, с одной стороны, в порядке появления альбомов, а с другой — от большего влияния музыканта к меньшему. Только через википедию я узнал, что Адриан Белью (преимущественно поп-рок и эксперименты), игравший с неким Френком Заппой (джаз-рок) и известный мне по группе "Кинг Кримсон" (преимущественно прог-рок), появлялся у Жана Мишеля Жарре (эмбиент, электроника) и Лори Андерсон (эксперименты, арт-рок, тоже, кстати, у Жарре появлялась). На первый взгляд связи между британским рок-гитаристом и французом-электронщиком нет, жанры разные, но, мне кажется, мало кто слушает только один жанр (это как слушать только одну группу). Мне нравится и тот, и другой, и все остальные из перечисленных — и если бы я знал об этих связях, то я бы послушал все это гораздо раньше.
Лайк👍
В целом очень интересный за блог. Случайно зашел и увлекся чтением. Спасибо.
Спасибо за статью! Было бы интересно послушать про программные реализации рекомендательных систем.
Да, статья обзорная, хорошая, спасибо! но было бы действительно очень интересно посмотреть и почитать про готовые решения, может быть есть уже скрипты или что то такое, что можно применить для старта разработки своей системы в интернет магазине.
Спасибо за статью. Очень доходчиво. Теперь ясно куда копать дальше. P.S. У Вас очень симпатичный и информативный блог! Спасибо.
👍
нужен прогер для разработки БД. идеи даны. artillustrator логин в вк