≡

В среднем за день я открываю Google Translate в два раза чаще, чем Facebook. Переводя очередной ценник в супермаркете, я уже не ощущаю тёплое дыхание киберпанка — это будничная реальность. А ведь исследователи почти столетие бились над алгоритмами машинного перевода, половину из которого без особых успехов. Однако именно их наработки теперь лежат в основе абсолютно всех современных систем обработки языка — от поисковиков до микроволновок с голосовым управлением. Сегодня поговорим как развивался и как устроен онлайн-перевод.
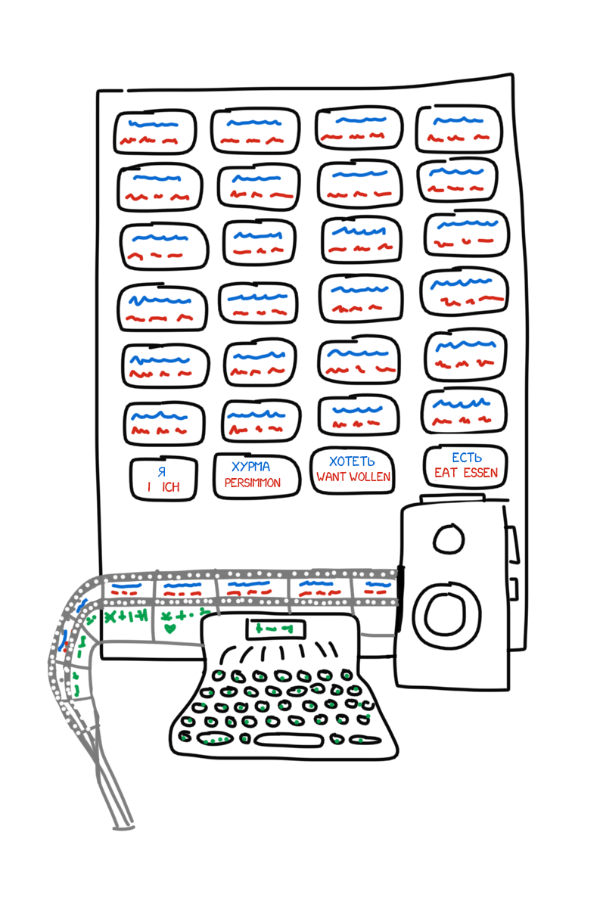
Наша история начинается в 1933 году. Советский ученый Пётр Троянский обращается в Академию Наук СССР с изобретённой им «машиной для подбора и печатания слов при переводе с одного языка на другой». Машина была крайне проста: большой стол, печатная машинка с лентой и плёночный фотоаппарат. На столе лежали карточки со словами и их переводами на четырёх языках.
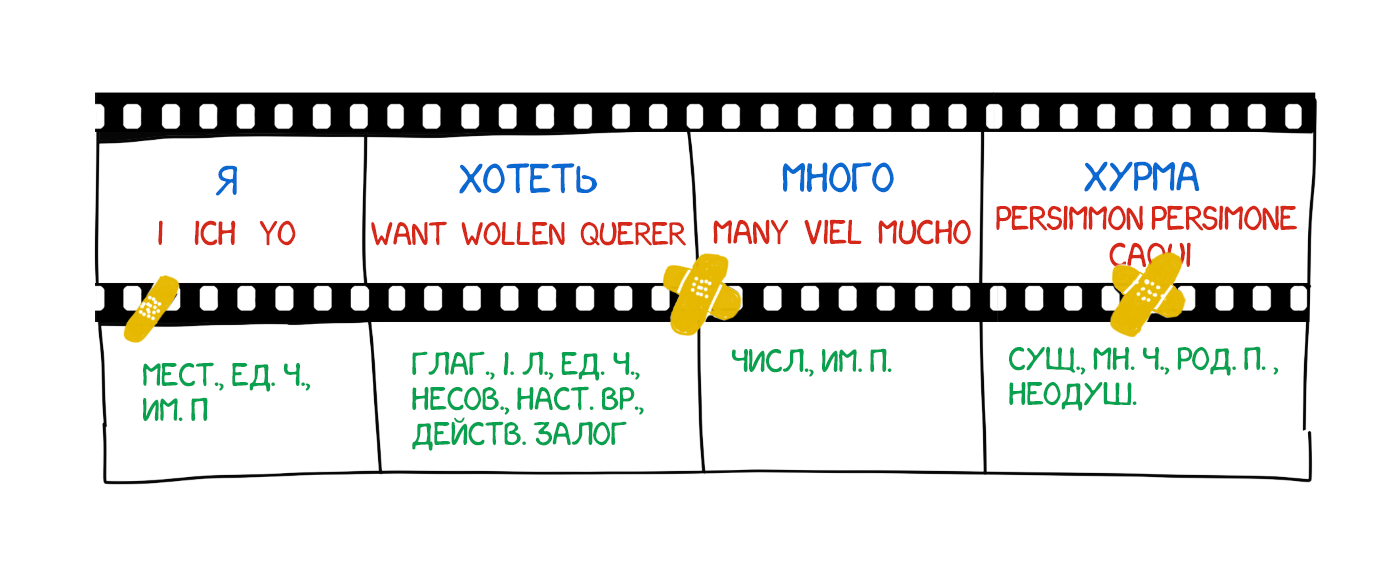
Оператор брал первое слово из текста, находил с ним карточку, фотографировал её, а на печатной машинке набирал его морфологическую информацию — «существительное, множественное число, родительный падеж». Её клавиши были модифицированы для удобства, каждая однозначно кодировала одно из свойств. Лента печатной машинки и плёнка камеры подавались параллельно, на выходе формируя набор кадров со словами и их морфологией:
Полученная лента отдавалась знающим конкретные языки лингвистам, которые превращали набор фотографий в связный литературный текст. Получается, чтобы переводить тексты как оператору, так и лингвистам требовалось знать только свой родной язык. Машина Троянского впервые на практике реализовала тот самый «промежуточный язык» (interlingua), о создании которого мечтали еще Лейбниц и Декарт.
По классике в СССР изобретение признали «ненужным», Троянский умер от стенокардии, 20 лет пытаясь её доработать. Никто в мире так и не знал о машине, пока его патенты не откопали в ахивах два других советских ученых в 1956 году. Произошло это не случайно.
Они искали ответ на вызов холодной войны, ведь 7 января 1954 года в штаб-квартире IBM в Нью-Йорке происходит Джорджтаунский эксперимент. Компьютер IBM 701 впервые в мире автоматически перевёл 60 предложений с русского языка на английский. «Девушка, которая не понимает ни слова на языке Советов, набрала русские сообщения на перфокартах. Машинный мозг сделал их английский перевод и выдал его на автоматический принтер с бешеной скоростью — две с половиной строки в секунду», — сообщалось в пресс-релизе компании IBM.

Газеты пестрили ликующими заголовками, но никто не говорил, что примеры для перевода были тщательно подобраны и оттестированы, чтобы исключить любую неоднозначность. Для повседневного использования эта система подходила не лучше карманного разговорника. Но гонка вооружений была запущена. Канада, Германия, Франция и особенно Япония тоже подключились к гонке за машинный перевод.
Сорок лет ученые бились в попытках улучшить машинный перевод, но тщетно. В 1966 американский комитет ALPAC публикует свой знаменитый отчёт, в котором называет машинный перевод дорогим, неточным и бесперспективным. Отчёт рекомендует больше сфокусироваться на разработке словарей, чем на машинном переводе, из-за чего иследователи из США практически на десятилетие выбывают из гонки.
Несмотря на всё, именно попытки ученых, их исследования и наработки впоследствии лягут в основу всего современного Natural Language Processing. Поисковики, спам-фильтры, персональные ассистенты — всё это появится благодаря тому, что кучка стран сорок лет подряд пыталась шпионить друг за другом.
война - двигатель прогресса. так что все эти шпионские страсти с "русскими хакерами" нам всем на пользу.
где макет?
ахивах -> архивах
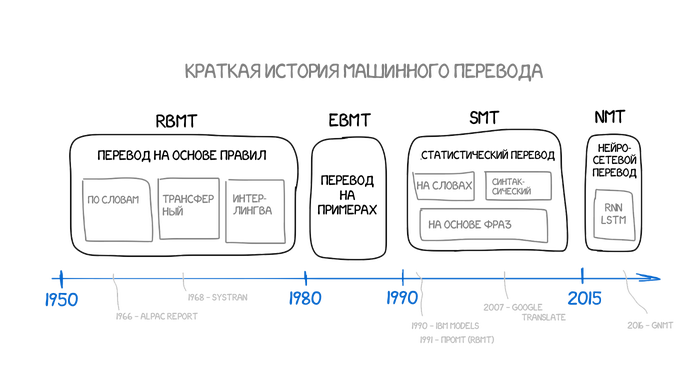
Привожу английские названия потому что именно эти аббревиатуры повсеместно используются в текстах и разговорах. Как HTTP или RSA, например.
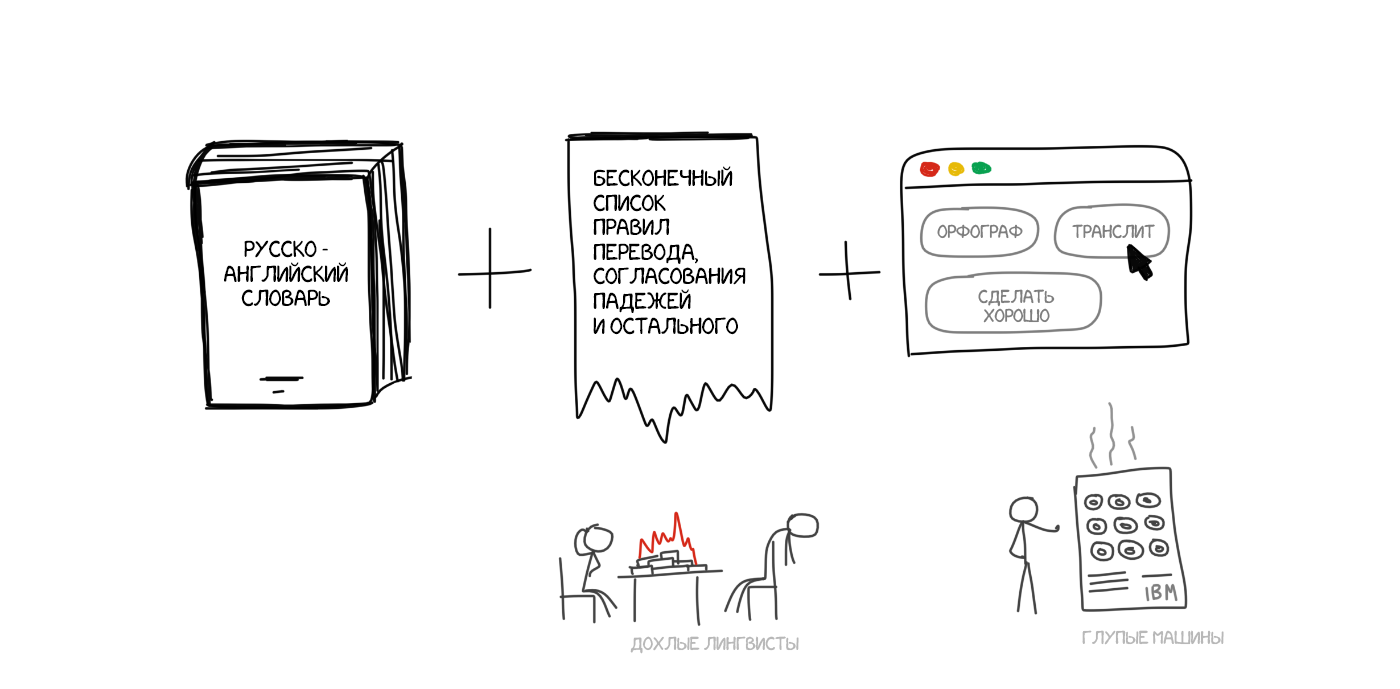
Идеи машинного перевода на основе правил начали появляться еще в 1970-х годах. Ученые подсматривали за работой лингвистов-переводчиков и пытались запрограммировать свои большие и медленные компуктеры повторять за ними. Их системы состояли из:
В общем-то всё. По желанию они дополнялись хаками типа списков имён, корректорами орфографии и транслитераторами.
ПРОМТ и Systran — самые известные примеры RBMT-систем. «Охладите траханье, углепластик, я рассматриваю её пользу», — золотое время же. Алиэкспресс вон до сих пор так переводит.
Но даже у них были свои нюансы и подвиды.
У этих систем удалось если не перевести, то хотя бы оставить тучу золотых копипаст, как те же Гуртовщики мыши например.
Kato, по показателю мемогенерации ПРОМТ еще долго никто не догонит, это да
vas3k, думаю, и не догонит. монгольский скайнет мог бы, но он в итоге больше пугал
А вот и нет, а вот и нет. У нас тоже мл, но проблема в том, как пишут тайтлы сами продавцы.
Макс, вы из алиэкспресса? Где мои наушники!?
Самый простой способ машинного перевода, понятный любому пятикласснику. Делим текст по словам, переводим каждое, немножко правим морфологию, чтобы звучало не криво, согласуем падежи, окончания и остальной синтаксис. Специально обученные лингвисты по ночам пишут правила под каждое слово.
На выходе получаем что-то переведённое. Чаще всего полное говно. Только лингвистов зря попортили.
В современных системах подход не используется вообще, рассказываю чисто поржать.
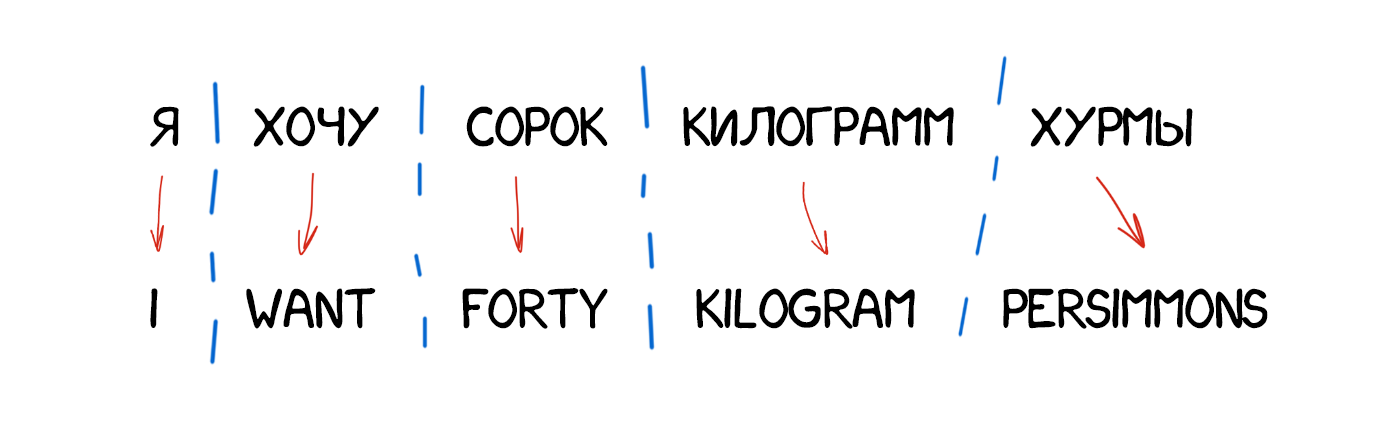
Уроки английского на 42fm? =)
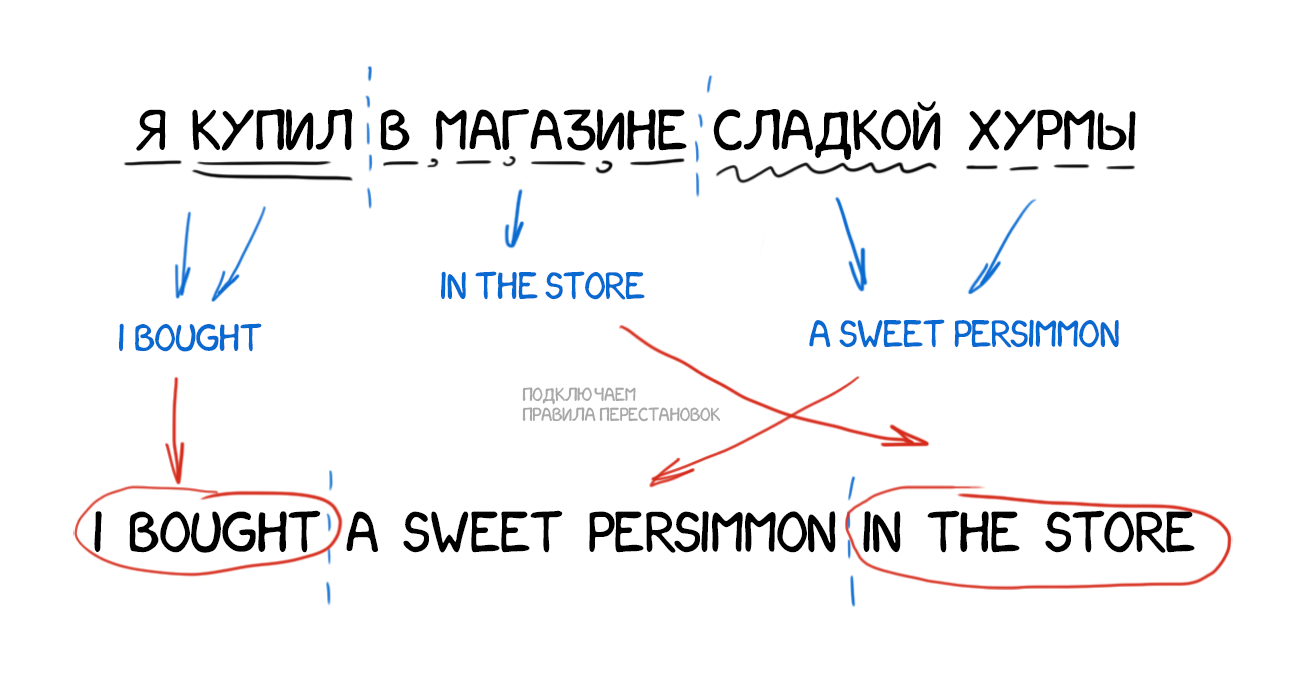
В них мы не кидаемся сразу переводить по словарю, а немного готовимся. Разбираем текст на подлежащее, сказуемое, ищем определения и всё остальное как учили в школе. Взрослые дядьки говорят «выделяем синтаксические конструкции». После этого в систему мы уже не закладываем правила перевода каждого слова, а манипулируем целыми конструкциями. В теории даже можем добиться более-менее неплохой конвертации порядка слов в языках.
На практике всё еще тяжело, лингвисты по-прежнему гибнут от физического истощения, а перевод получается фактически дословный. С одной стороны проще: можно задать общие правила согласования по роду и падежу. С другой сложнее: сочетаний слов намного больше, чем самих слов. Каждый вариант не учтешь руками.
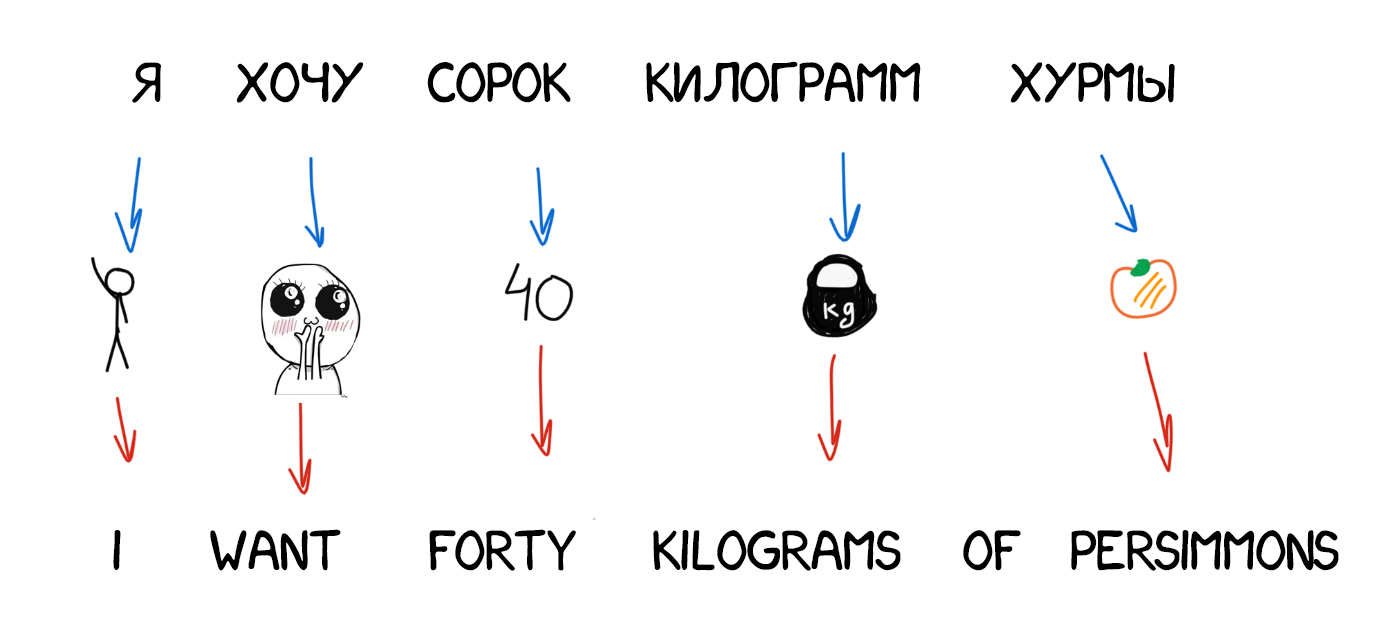
Полностью конвертируем исходное предложение в некое промежуточное представление, единое для всех языков мира (interlingua). В ту самую интерлингву, которой грезил сам Декарт. Специальный метаязык, правила которого едины и покрывают все языки мира, тем самым превращая перевод в техническую задачу перегона туда-сюда. Специальные парсеры затем конвертируют эту интерлингву в нужный язык и вот она сингулярность.
Часто интерлингву путают с трансферными системами, ведь там тоже есть конвертация. Однако в трансферных системах правила конвертации пишутся под два конкретных языка, а в интерлингвистической между каждым языком и интерлингвой. Добавив в интерлингвистическую систему третий язык, мы сможем переводить между всеми тремя, а в трансферной нет.
В реальной жизни всё оказалось не так сладко. Создать универсальную интерлингву вручную оказалось крайне сложно. Некоторые учёные жизни свои положили на это. Ничего не получилось, однако благодаря им у нас появились методы морфологического, синтаксического и даже иногда семантического анализа. Одна только модель Смысл <-> Текст чего стоит.
Но сама идея промежуточного языка еще вернётся к нам позже. Надо будет всего 30 лет подождать.
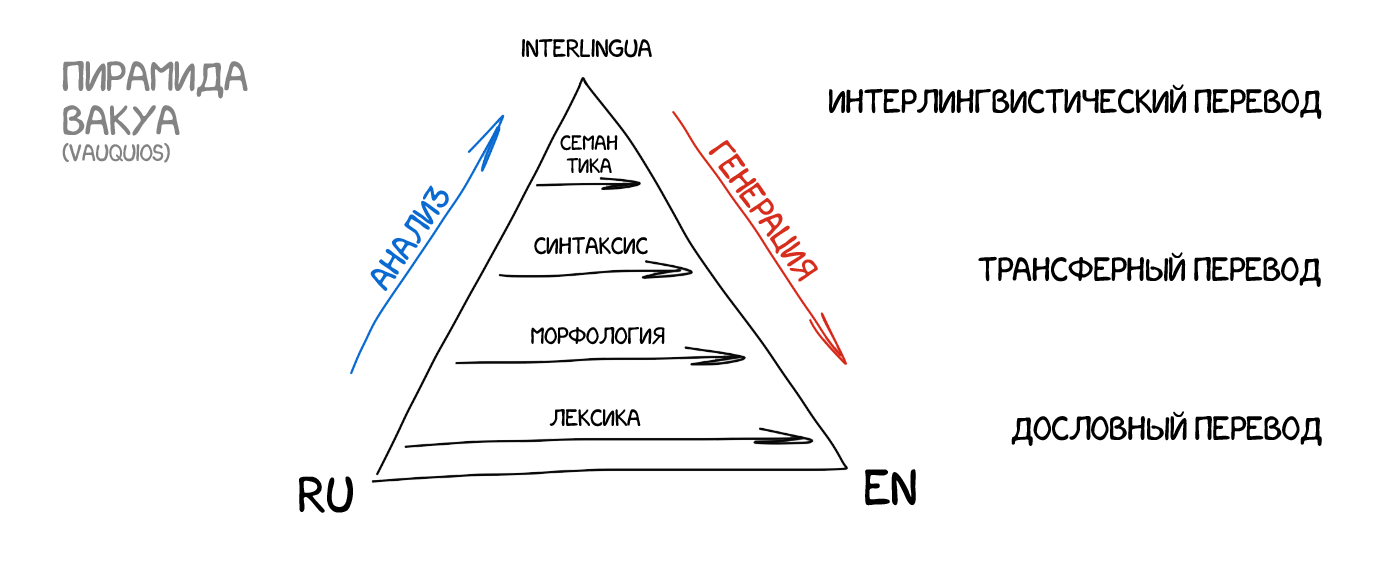
Как можно заметить, все RBMT тупы, ужасны, потому сейчас редко используются. Разве что в специфических местах типа перевода метеосводок. Среди плюсов RBMT отмечают морфологическую точность (не путает слова), воспроизводимость (все переводчики получат одинаковый результат) и возможность затюнить под предметную область (обучить специальным терминам экономистов или программистов).
Даже если представить, что учёным и удалось бы создать идеальную RBMT, а лингвистам заложить в неё все правила правописания, за дверью их уже поджидало веселье — исключения. Неправильные глаголы в английском, плавающие приставки в немецком, суффиксы в русском, да и просто ситуации, когда «у нас так не говорят, надо вот так». Попытка учесть все нюансы оборачивается миллионами потраченных зря человекочасов.
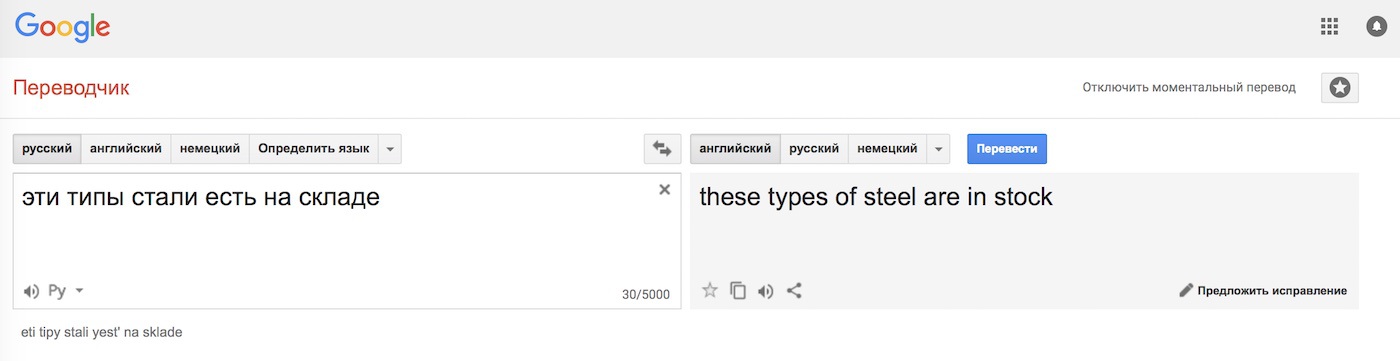
Куча правил всё равно не решает главной проблемы — омонимия. Одно и то же слово может иметь разный смысл зависимости от контекста, а значит отличается и его перевод. Вспоминается пример с одной из старых лекций Сегаловича: «Эти типы стали есть на складе». Он говорил, что может найти четыре разных варианта прочтения этого предложения. А вы?
Наши языки развивались отнюдь не на основе грамматик и правил, о которых любят рассуждать лингвисты. Они больше зависят от того, кто на кого напал и завоевал за последние триста лет. Вот как мне теперь обучить этому машину?
За сорок лет холодной войны ученые так и не смогли найти внятного решения. RBMT сдох.
1 - "есть несколько типов доширака, некоторыми из них питаются на складе", 2 - "на склад пришли типы с раёна и начали там жрать", 3 (скучное) - "на складе есть сталь нескольких видов". 4 - ?
4-Если вы хотите покушать этих видов стали(ну мало ли, кто питается сталью), то идите на склад и там ешьте.
1 - "эти типы с района стоят и жрут на территории склада", 2 - "эти типы голубей стали кушать на складе", 3 - "такие типы стали нужно кушать на складе, если любите похрустеть зубами", 4 - "такие типы стали находятся на складе"
5 - Эти пацаны перестали есть внутри, а стали есть на крыше склада
6 - Стало принято есть на складе, хоть бы и эти типы стали
В битве за машинный перевод в те годы была особенно заинтересована Япония. Там не было холодной войны, но были свои причины: крайне мало кто в стране знал английский. Это сулило большие трудности на вечеринке наступающей глобализации, из-за чего японцы были крайне мотивированы найти рабочий метод машинного перевода.
Англо-японский перевод на основе одних только правил крайне сложен, строение языков отличается, почти все слова приходится переставлять и добавлять новые. В 1984 году учёному университета Киото по имени Макото Нагао приходит идея. А что если не пытаться каждый раз переводить заново, а использовать уже готовые фразы?
Предположим нам надо перевести предложение «я иду в магазин». Где-то в заначке у нас уже есть перевод похожей фразы «я иду в театр» и словарь с переводом слова «магазин». Мы ведь можем как-то попытаться вычислить разницу и перевести только одно слово в имеющемся примере, не похерив остальные конструкции. И чем больше у нас примеров — тем лучше перевод.
Я же тоже так строю фразы на незнакомых языках!
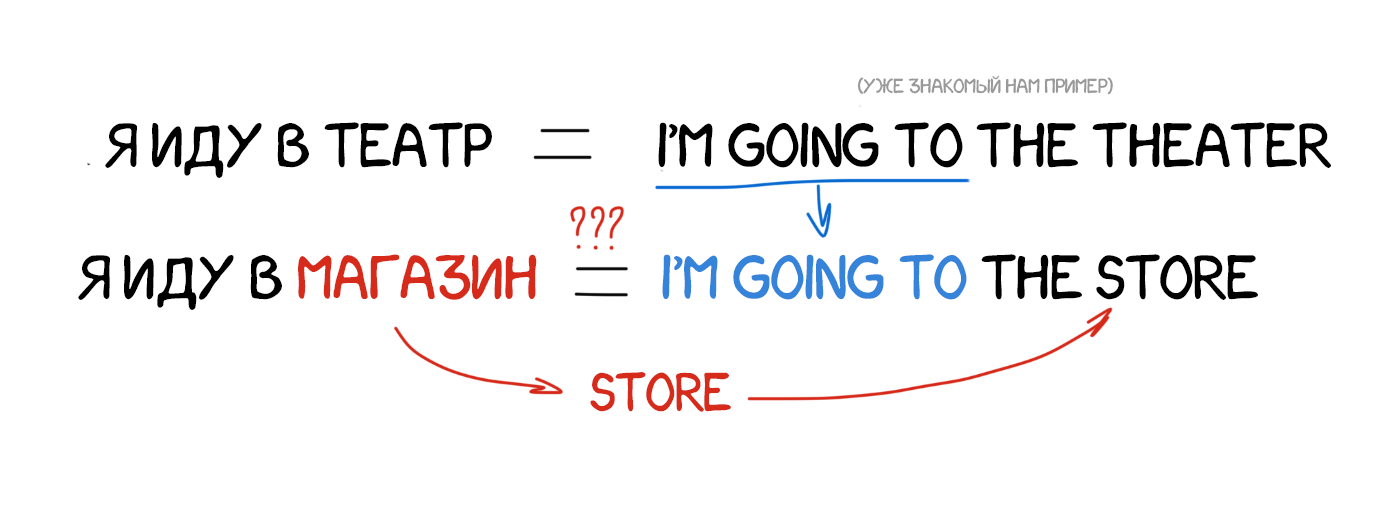
Историческая важность метода была в том, что ученые всего мира впервые прозрели: можно не тратить годы на создание правил и исключений, а просто взять кучу уже имеющихся переводов и скормить их машине. Это была еще не революция, но шаг туда. До революции и изобретения статистического перевода оставалось пять лет.
На рубеже 1990 года в исследовательском центре IBM впервые показали систему машинного перевода, которая ничего не знала о правилах и лингвистике. Учёные показали бездушному компьютеру очень много одинаковых текстов на двух языках, и заставили его разбираться в закономерностях самому.
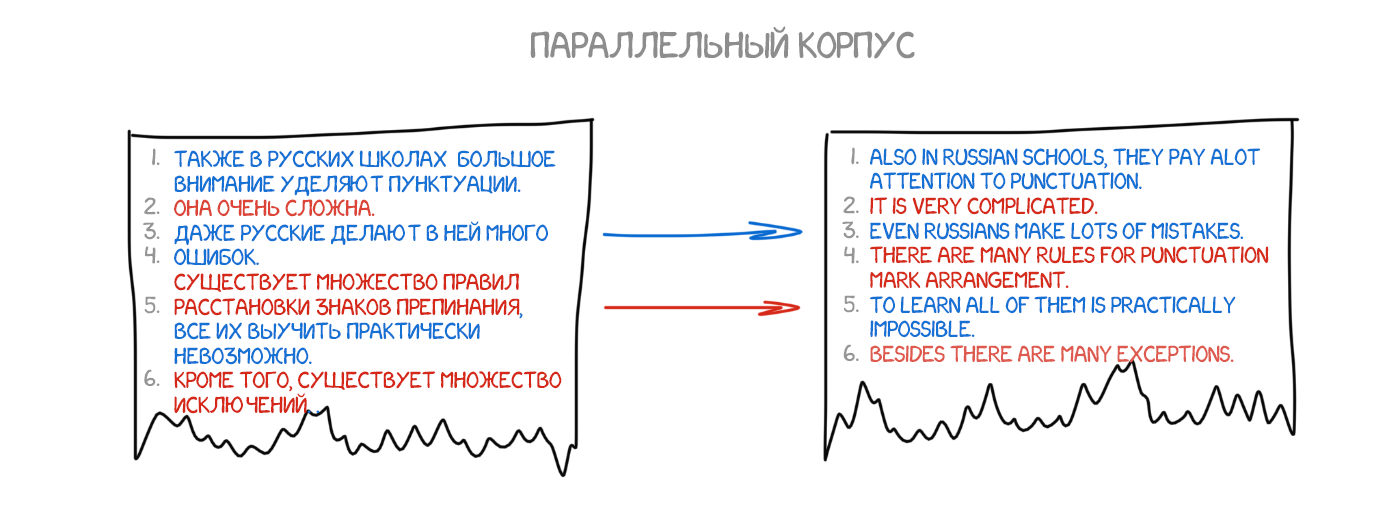
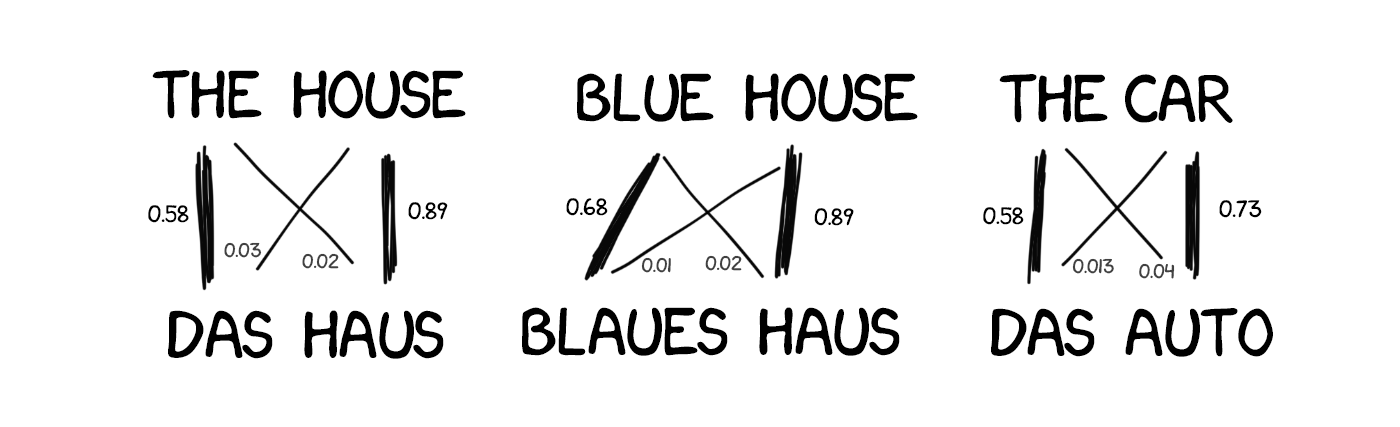
Идея была проста и одновременно красива: берем одно предложение на двух языках, разбиваем его по словам и пытаемся сопоставить каждое слово с его с переводом. Повторяем эту операцию где-то 500 млн раз, а машина считает сколько раз у нас слово das Haus переводилось как house, building, construction, итд. Наверное чаще всего это был house, его и будем использовать. Заметьте, мы не задали ни правил, ни словарей. Машина сама всё нашла, руководствуясь чистой статистикой и логикой «люди переводят вот так, значит и я буду». Так родился статистический перевод.
Точность таких переводчиков оказалась заметно выше всех предыдущих, а разработка не требовала никаких лингвистов. Находим больше текстов — улучшаем перевод.
Одна проблема: как машина догадается, что для das Haus парой является именно house, а не любое другое слово из предложения? Порядок слов-то разный, откуда мы знаем как именно надо разбить и найти нужные слова?
Ответ: никак. В начале работы машина с равной долей вероятности считает, что слово das Haus переводится как любое из слов имеющегося предложения. Когда она встречает das Haus в других предложениях, то количество переводов das Haus как house начинает увеличиваться с каждым разом. Это называется «алгоритмом выравнивания слов» (word aligment). Типична задача машинного обучения, такие решают в универах.
Машине нужны миллионы и миллионы предложений на двух языках, чтобы набрать статистику по каждому слову. И где столько взять? Так вон, в Европарламенте и совете ООН ведут конспекты заседаний на языках всех стран-членов, их и возьмем. Сейчас они даже открыли для скачивания: UN Corpora и Europarl Corpora.
Первые системы статистического перевода опять начали с деления по словам. Это казалось логично и просто. Первую изобретённую модель статистического перевода в IBM назвали IBM Model 1. Изящно, да. Догадайтесь как назвали вторую?
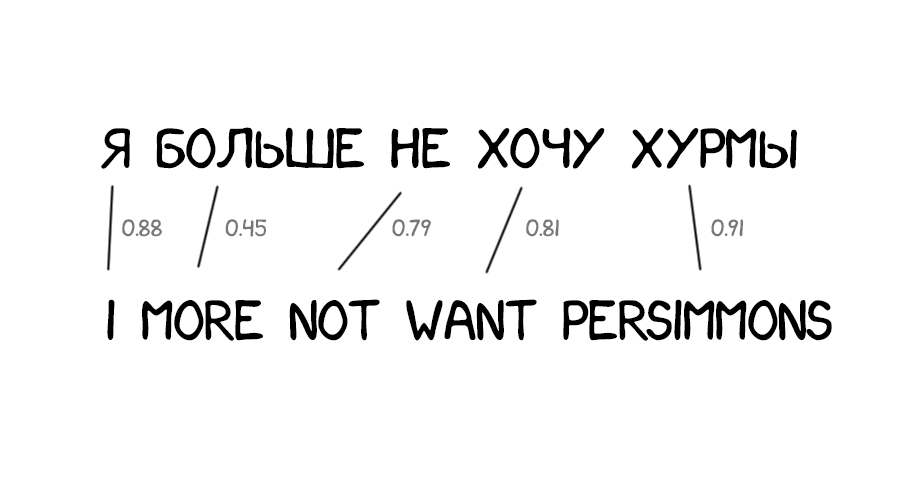
Классический подход — делим всё на слова и считаем статистику. Никакого учёта порядка или перестановок. Из хитростей Model 1 умела разве что переводить одно слово в несколько. Der Staubsauger (пылесос) легко превращался в Vacuum Cleaner, но обратно уже как повезет.
На питоне можно найти простенькие реализации: shawa/IBM-Model-1.
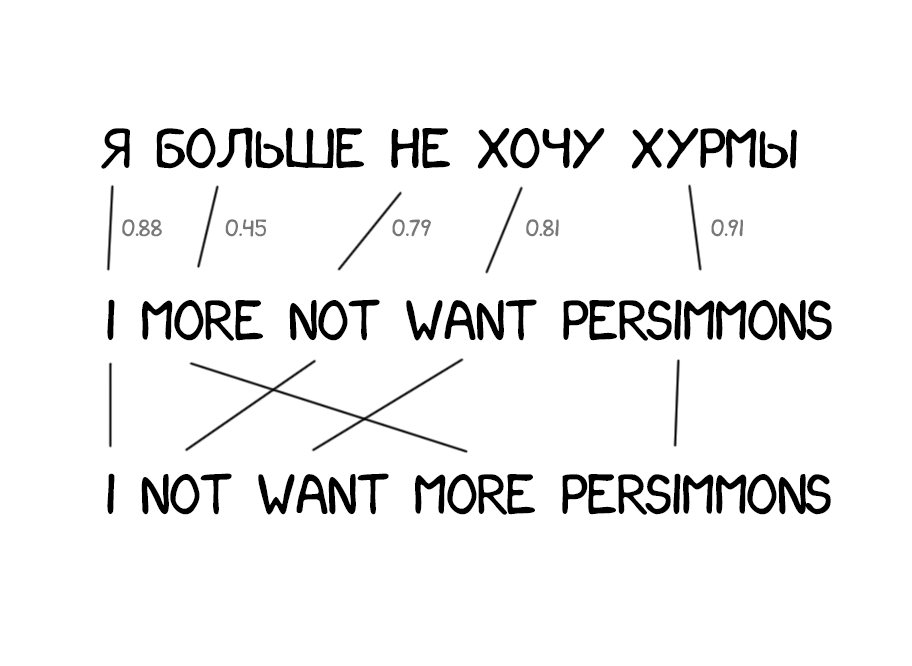
Отсутствие знаний о порядке слов в языках стало проблемой для Model 1. В некоторых он очень важен. Потому в Model 2 стали запоминать на каком месте появляется в переведённом предложении. Добавили промежуточный шаг — после перевода машина пыталась переставить слова местами так, как она думала будет звучать более естественно.
Стало лучше, но всё еще хреново.
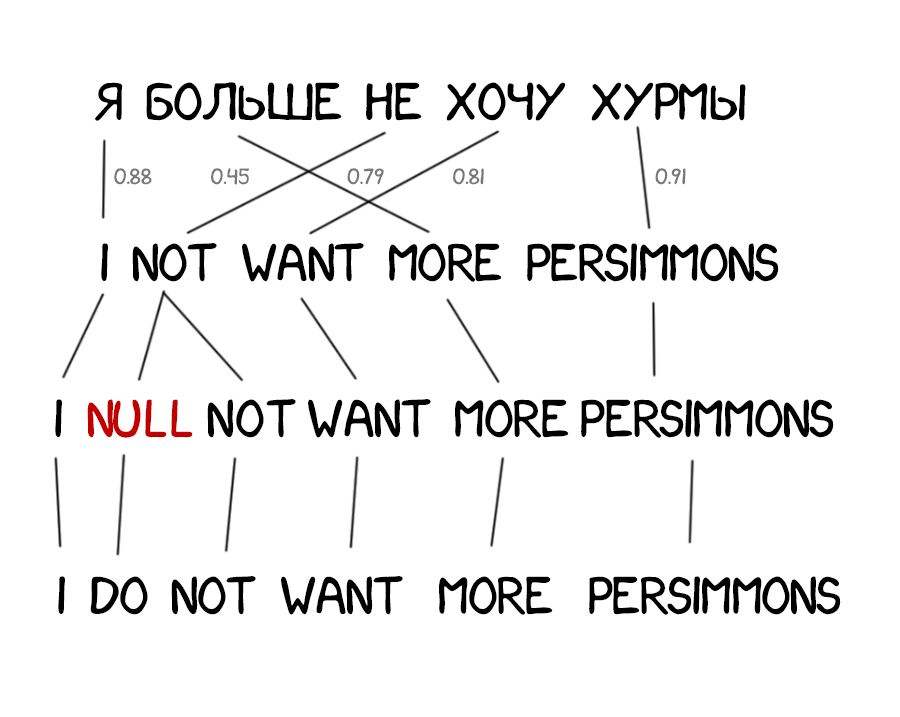
Часто при переводе появляются новые слова, которых не было в оригинальном тексте. В немецком языке внезапно вылезают артикли, в английском вставляют глагол do где не попадя. «Я не хочу хурмы» → «I do not want persimmons. Чтобы решить эту проблему в Model 3 добавили два промежуточных шага:
Model 2 хоть учитывала порядок слов в предложении, но ничего не знала про перестановки слов между собой. Часто при переводе надо, например, поменять существительное и прилагательное местами. Тут сколько ни запоминай их порядок по всему предложению — лучше не станет. Потому в Model 4 стали учитывать еще и так называемый «относительный порядок». Если при переводе два слова постоянно менялись друг с другом — модель это запоминала.
Особо ничего нового. В Model 5 добавили параметров для обучения и пофиксили проблемы, когда два слова конфликтовали за место в предложении.
ни попадя
ол
Несмотря на всю революционность, Word-based системы по прежнему ничего не могли поделать с падежами, родом и омонимией. Каждое слово они переводили единственным, по их мнению, верным способом. Сейчас такие системы не используются, их заменил более продвинутый метод — перевод по фразам.
Про омонимию у меня есть любимая шутка:
— Это ваш Ягуар у подъезда стоит?
— Да
— Я допью?
отличный пример, краду в свою копилку :)
xm02, баян же тысячелетний =)
xfynx, тысячелетний - это про "squirrel Institute", а этот крутой :)
а в чем двусмысленность-то
є Ягуар енергетичний напиток і є Ягуар-марка машини
Torro, боже, напиток... НАПІЙ! Почему я один если не уверен в правильности написанного проверяю орфографию гугля слово? XD
Взял за основу все принципы перевода по словам: статистика, перестановки и лексические хаки. Но для обучения он разбивал текст не только на слова, но и на целые фразы. Точнее N-граммы или фраземы — пересекающиеся наборы из N слов подряд. Машина училась переводить устойчивые сочетания слов, что заметно улучшило точность.
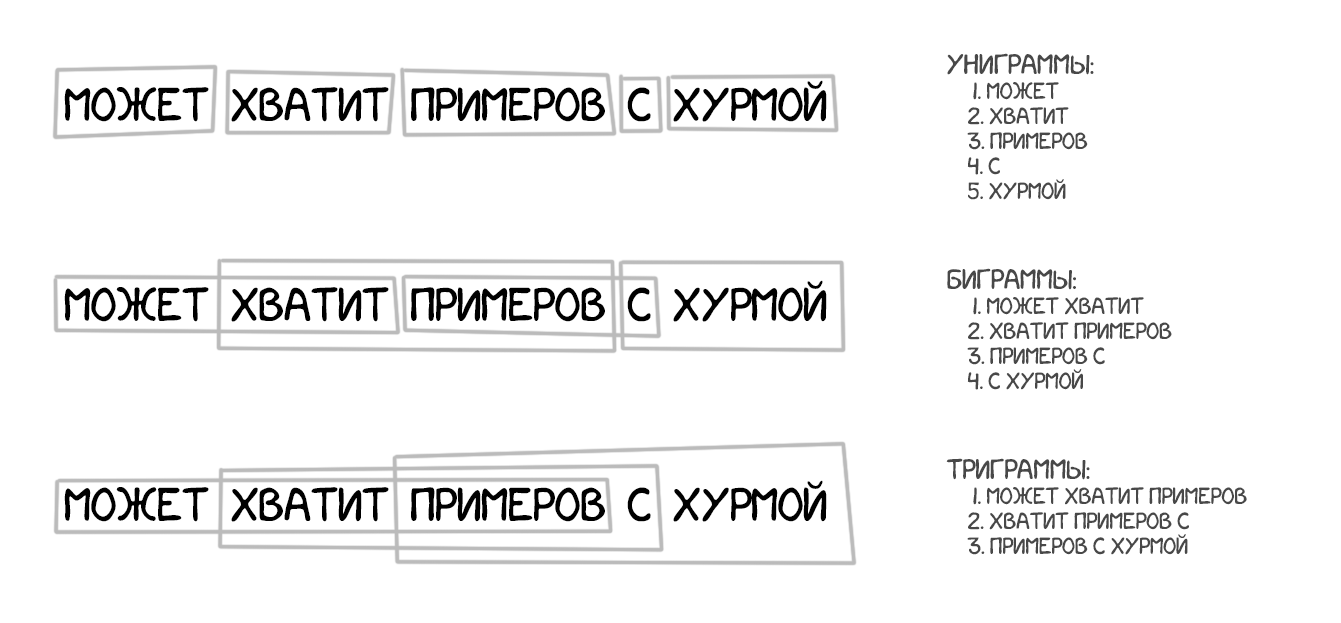
Хитрость метода заключалась в том, что «фразы» не всегда были понятными нам со школы синтаксическими конструкциями. Как только в перевод пытался вмешиваться человек, знающий про лингвистику и строение предложений, качество перевода резко падало. Пионер компьютерной лингвистики Фредерик Йелинек однажды пошутил по этому поводу: «Каждый раз, когда из команды уходит линвист, качество распознавания возрастает».
Помимо улучшения точности, перевод по фразам дал больше свободы в поиске двуязычных текстов для обучения. Для Word-based перевода было очень важно точное соответствие переводов, что исключало любые литературные или вольные переводы. Phrase-based прекрасно обучался даже на них. Многие даже начали парсить новостные сайты на разных языках и улучшать перевод этими текстами.
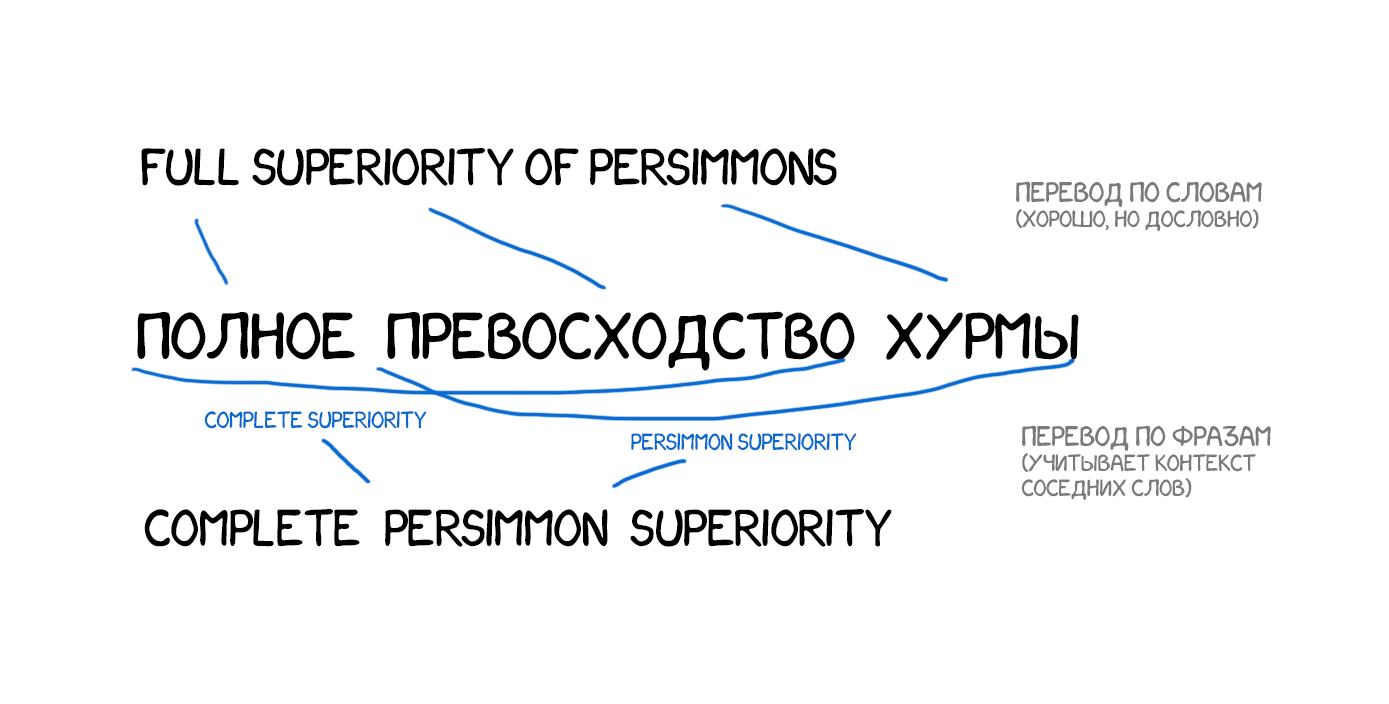
С 2006 года этот подход начали использовать все. Google Translate, Yandex, Bing и другие качественные онлайн-переводчики работали именно как Phrase-based аж до самого 2016-го. Каждый из вас может припомнить опыт, когда одно предложение Google переводил на отлично, литературно переставляя слова, а на другом начинал гнать полную околесицу. Такова особенность перевода по фразам.
Если старый добрый Rule-based подход стабильно давал предсказуемый, хоть и ужасный результат, то статистические методы бывало удивляли и озадачивали. Можно вспомнить десяток шуток про Google Translate, когда он переводил «three hundred» как «300» и даже не смущался. Этот косяк назвали статистическими аномалиями.
Phrase-based перевод стал настолько популярным, что когда вы слышите «статистический машинный перевод», скорее всего имеется в виду именно он. Вплоть до 2016 года во всех исследованиях Phrase-based перевод хвалебно называют the state-of-art. Тогда никто даже не подозревал, что в лабораториях Google уже завозят под это дело фуры с нейросетями, чтобы опять изменить наше представление о машинном переводе.
"уходит линГвист"
А в чём косяк, когда "гугл переводил «three hundred» как «300» и даже не смущался"? Что не в слово, а в цифры перевёл?
Стоит кратенько упомянуть и этот метод. До прихода нейросетей, про синтаксический перевод многие годы говорили как про «будущее переводчиков», но достичь успеха он так и не успел.
Адепты синтаксического перевода верили в объединение подходов SMT и старого трансферного перевода по правилам. Нужно научиться делать достаточно точный синтаксический разбор предложения — определять подлежащее, сказуемое, зависимые члены и вот это вот всё, а затем построить дерево. Имея такое дерево, можно обучить машину правильно конвертировать фигуры одного языка в фигуры другого, выполняя остальной перевод по словам или фразам. Только делать это теперь не руками, а машинным обучением. В теории это решило бы проблему порядка слов навсегда.
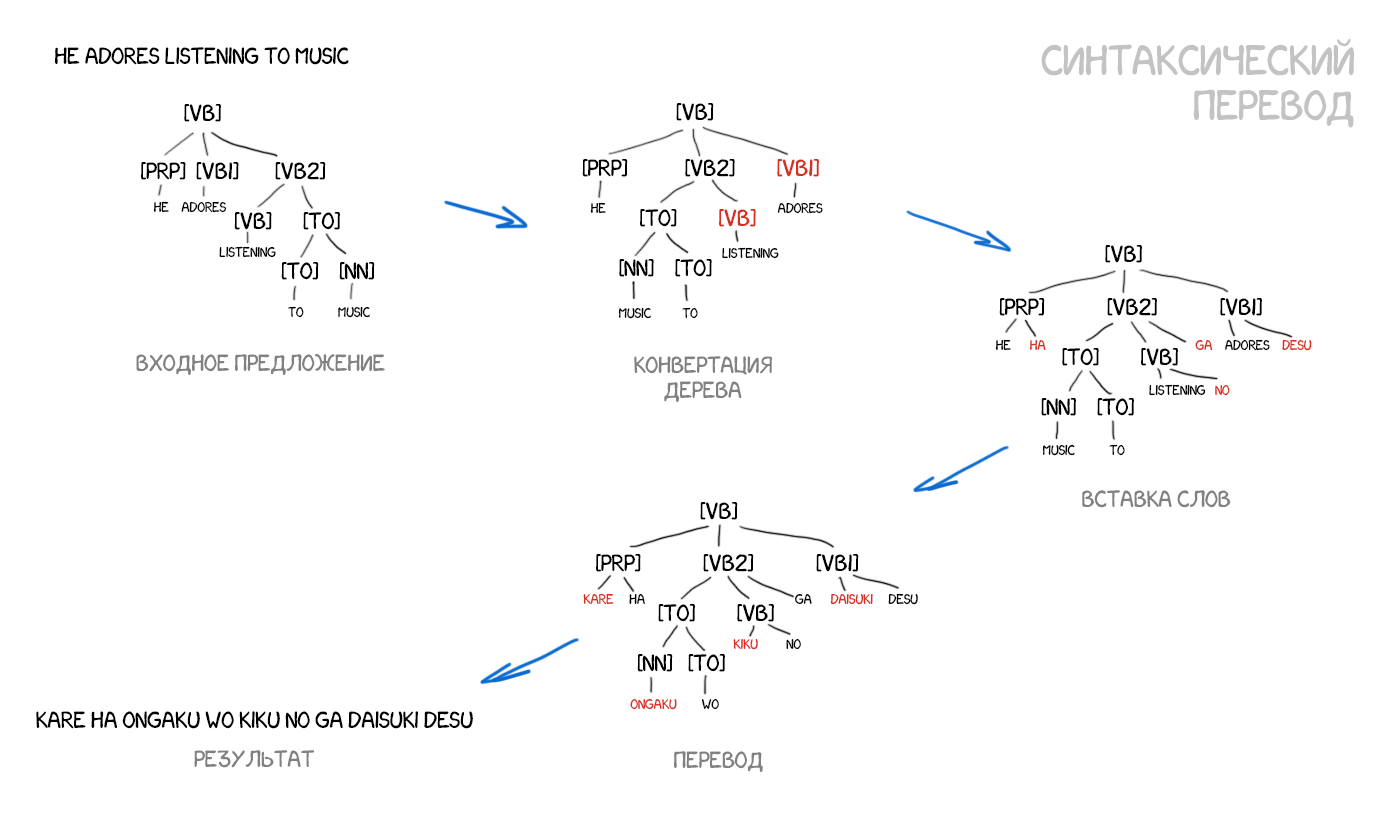
Проблема в том, что хоть человечество и считает проблему синтаксического разбора давно решенной (для многих языков есть готовые библиотеки), по факту он работает весьма говёно. Я лично много раз пытался использовать синтаксические деревья для задач сложнее вычленения подлежащего и сказуемого, и каждый раз отказывался в пользу других методов.
Если у вас был хоть один успешный опыт с ними, расскажите в комментах.
+1 c естественными языками ST дает так себе результаты, но есть другая идея - женить деревья синтаксические и онтологические
Это дает интересные результаты на специализированных текстах, ну и потом именно так примерно работает Палантир (там правда не про перевод) и некоторые абби продукты
говённо с двумя н
Broker, где можно почитать об этом?
В принципе есть нормальные парсеры для европейских языков. Но тут в другом трабл: если взять даже маленький корпус с простейшими деревьями с 2-3 уровнями всего, то неделю будешь ждать, пока оно натренируется...
В 2014 году выходит статья с кратким описанием идеи применения нейросетей глубокого обучения к машинному переводу. В верхнем интернете её вообще никто не заметил, а вот в лабораториях Google начали активно копать. Спустя два года, в ноябре 2016, в блоге Google появляется анонс, который и перевернул игру.
Идея была похожа на перенос стиля между фотографиями. Помните приложения типа Prisma, которые обрабатывали фоточки в стиле известного художника? Там не было особой магии — нейросеть обучили распознавать картины художника, а потом «оторвали» последние слои, где она принимает решение. Получившиеся кишочки, по сути промежуточное представление сети, и было той самой стилизованной картинкой. Она так видит, а нам красиво.

Если с помощью нейросети мы можем перенести стиль на фото, то что если попытаться подобным образом наложить другой язык на наш текст? Представить язык текста как тот самый «стиль художника», попытавшись его перенести, сохранив суть изображения (то есть суть текста).
Представьте, что я на словах описываю вам как выглядит моя собака: средний размер, острый нос, большие уши, короткий хвост и гавкает постоянно. Я передаю вам набор характеристик собаки и, при достаточно точном описании, вы сможете даже нарисовать её, хотя никогда вживую не встречали.
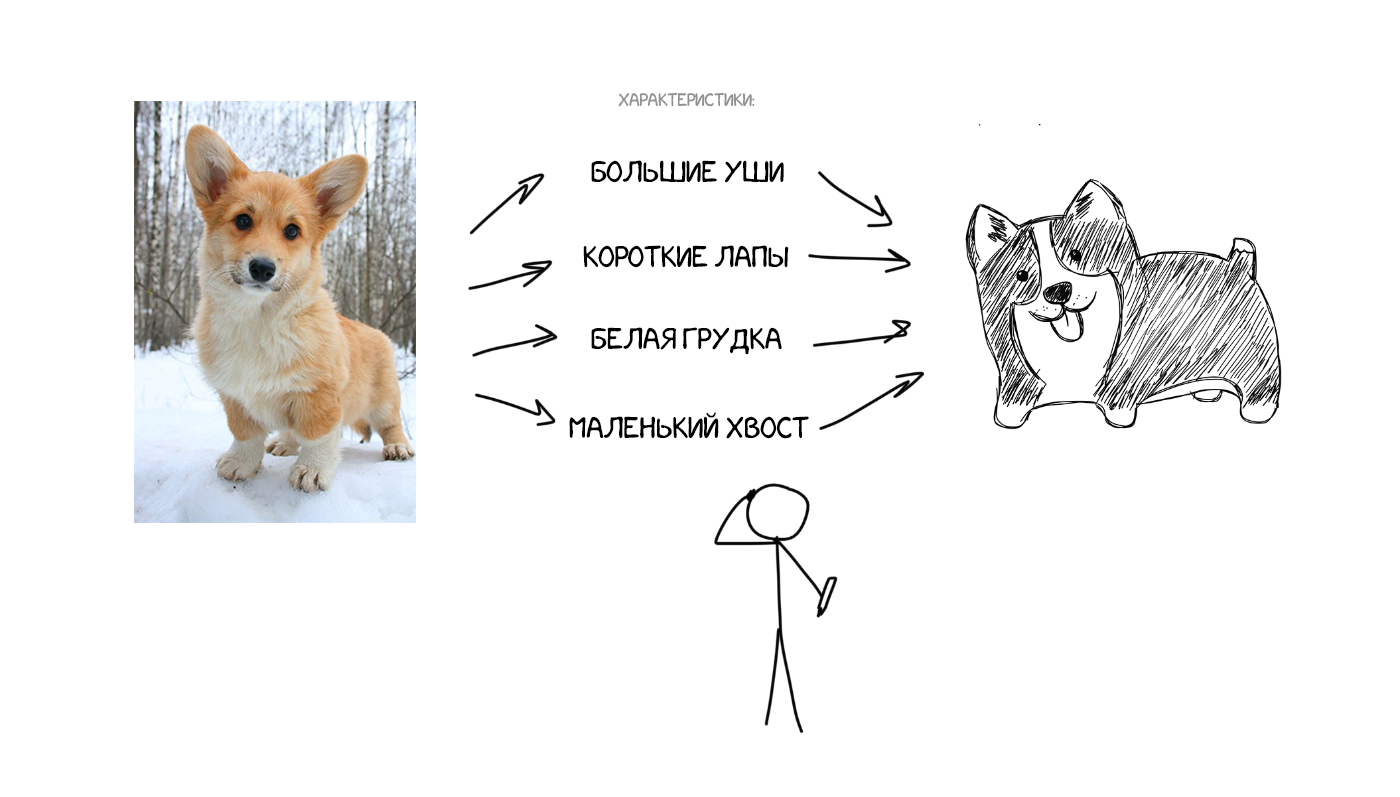
Теперь что если представить исходный текст как набор таких же характерных свойств? По сути закодировать его так, чтобы затем другая нейросеть — декодер, расшифровала их обратно в текст, но уже на другом языке. Мы специально обучим декодер знать только свой язык. Он и понятия не имеет откуда характеристики взялись, но умеет выразить их, скажем, на испанском. Продолжая аналогию: какая вам разница чем рисовать описанную мной собаку — карандашами, акварелью или пальцем по грязи. Рисуете как умеете.
Еще раз: первая нейросеть умеет только кодировать предложение в набор циферок-характеристик, а вторая только декодировать их обратно в текст. Обе понятия не имеют друг о друге, каждая знает только свой язык. Ничего не напоминает? К нам вернулась идея интерлингвы. Та-да.
Но как найти эти характеристики? С собакой всё понятно, у неё лапки и другие части тела, а с текстами как? Учёные 30 лет назад уже пытались скрафтить универсальный языковой код, это закончилось полным провалом.
Но у нас теперь есть диплернинг, который как раз этим и занимается! Главное отличие диплёрнинга от классических нейросетей как раз и было в том, что его сети обучаются находить характерные свойства объектов, не понимая их природы. При наличии достаточно большой нейросети и пары тысяч видеокарт в заначке, можно попытаться найти такие характеристики и в тексте!
Теоретически полученные нейросетями характеристики потом можно отдать лингвистам и они откроют для себя много нового. Яндекс об этом как-то рассказывал.
Вопрос только в том, какой вид нейросети использовать в кодере и декодере. Для картинок отлично подходят сверточные нейросети (CNN), потому что работают с независимыми блоками пикселей. Но в тексте не бывает независимых блоков, каждое следующее слово зависит от предыдущих и даже последующих. Текст, речь и музыка всегда последовательны. Для их обработки лучше подходят реккурентные нейросети (RNN), ведь они помнят предыдущий результат. В нашем случае это предыдущие слова в предложении.
RNN сейчас применяют много где: распознавание речи в Siri (парсим последовательность звуков, где каждый зависит от предыдущего), подсказки слов на клавиатуре (запоминаем предыдущие и угадываем следующее), генерация музыки, даже чатботы.
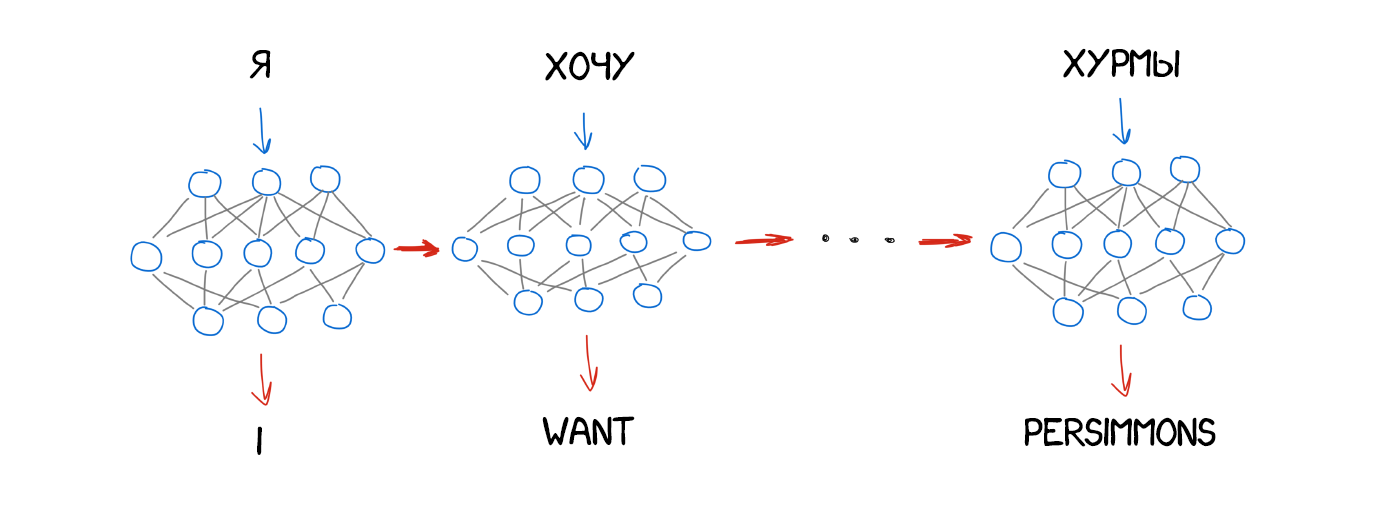
Для задротов типа меня: на самом деле, архитектуры нейронных переводчиков сильно разнятся. Сначала исследователи использовали обычные RNN, потом перешли на двунаправленные — переводчик учитывал не только слова до, но и после нужного слова. Так было куда эффективнее. Потом вообще пошли по-хардкору, используя многослойные RNN с LSTM-ячейками для долгого хранения контекста перевода.
За два года нейросети превзошли всё, что было придумано в переводе за последние 20 лет. Нейронный перевод делал на 50% меньше ошибок в порядке слов, на 17% меньше лексических и на 19% грамматических ошибок. Нейросети даже научались сами согласовывать род и падежи в разных языках, никто их этому не учил.
Самые заметные улучшения были там, где никогда не существовало прямого перевода. Методы статистического перевода всегда работали через английский язык. Если вы переводили, например, с русского на немецкий, машина сначала перегоняла текст в английский, а только потом переводила на немецкий. Двойные потери. Нейронному переводу это не нужно — подключай любой декодер и погнали. Впервые стало возможно напрямую переводить между языками, у которых не было ни одного общего словаря.
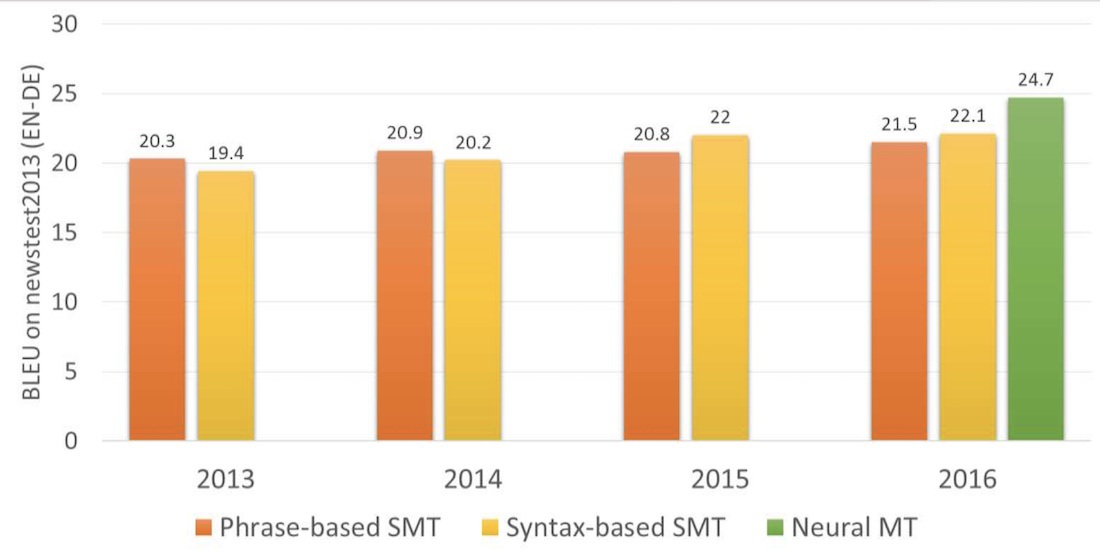
В 2016 году Google включил нейронный перевод девяти языков между собой, в 2017 был добавлен и русский. Google разработал собственную систему под нехитрым названием Google Neural Machine Translation (GNMT), состоявшую аж из 8-слойного RNN на входе и такого же на выходе и системы согласования контекста под названием Attention Model.
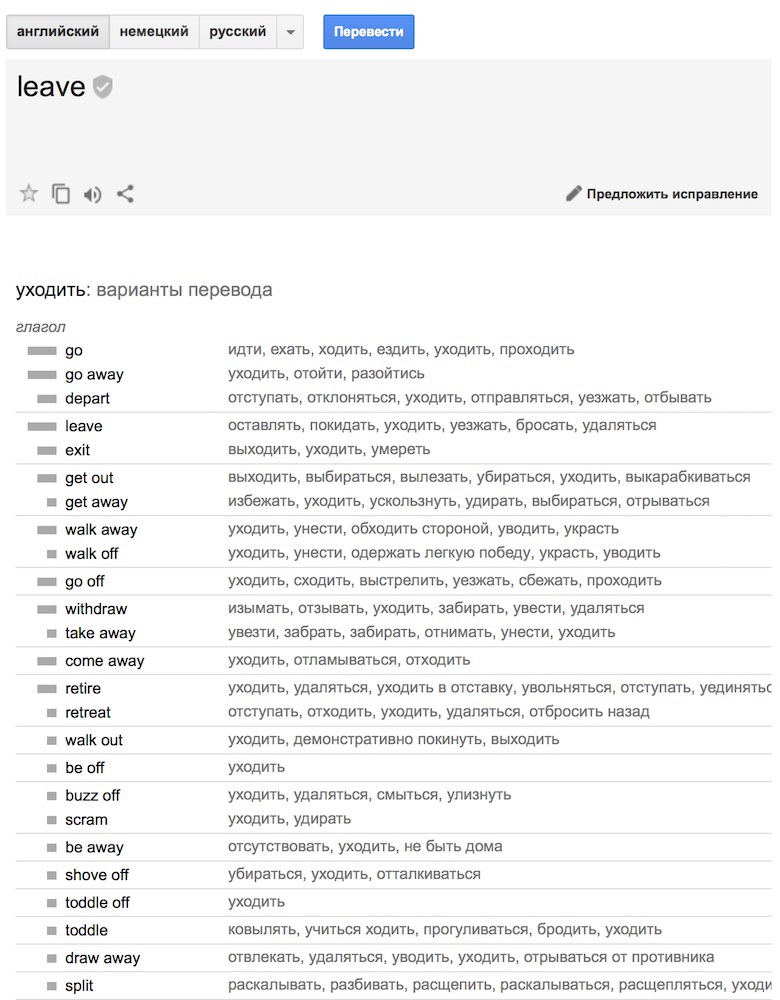
При обучении они не просто разбивали предложения по фразам и словам, они делили даже сами слова на части. Этим они пытались решить одну из главных проблем NMT — они беспомощны, когда слова нет в их словарном запасе. Например «Вастрик». Вряд ли кто-то обучал нейросеть переводить мой никнейм. В этом случае GMNT пытается разобрать его на части и склеить из них перевод. Хитро.
Hint: тот Google Translate, который переводит сайты в браузере, всё еще использует старый Phrase-based алгоритм. Почему-то Google его не обновляет и на нём очень заметны отличия по сравнению с онлайн-версией.
В онлайн-версии Google Translate сделали еще и механизм краудсорсинга переводов. Сейчас пользователи могут выбрать наиболее правильную по их мнению версию перевода, и если так многим она понравится, Google будет всегда переводить эту фразу именно так, помечая специальным значком. Очень круто работает на коротких повседневных фразах типа «пойдем на обед» или «буду ждать внизу». Гугл знает разговорный английский лучше меня :(
Переводчик Bing от Microsoft работает как полная копия Google Translate. А вот Яндекс отличается.
Яндекс запустил свой нейросетевой перевод в 2017 году. Главным отличием они заявили гибридность. Переводчик Яндекса переводит предложение сразу двумя методами — статистическим и нейросетевым, а потом с помощью их любимого алгоритма CatBoost находит наиболее подходящий.
Дело в том, что нейронный перевод плохо справляется с короткими фразами. Когда вам надо перевести словосочетание типа «сиреневая бетономешалка», нейросети могут нафантазировать лишнего, а простой статистический перевод найдет оба слова тупо, быстро и без проблем.
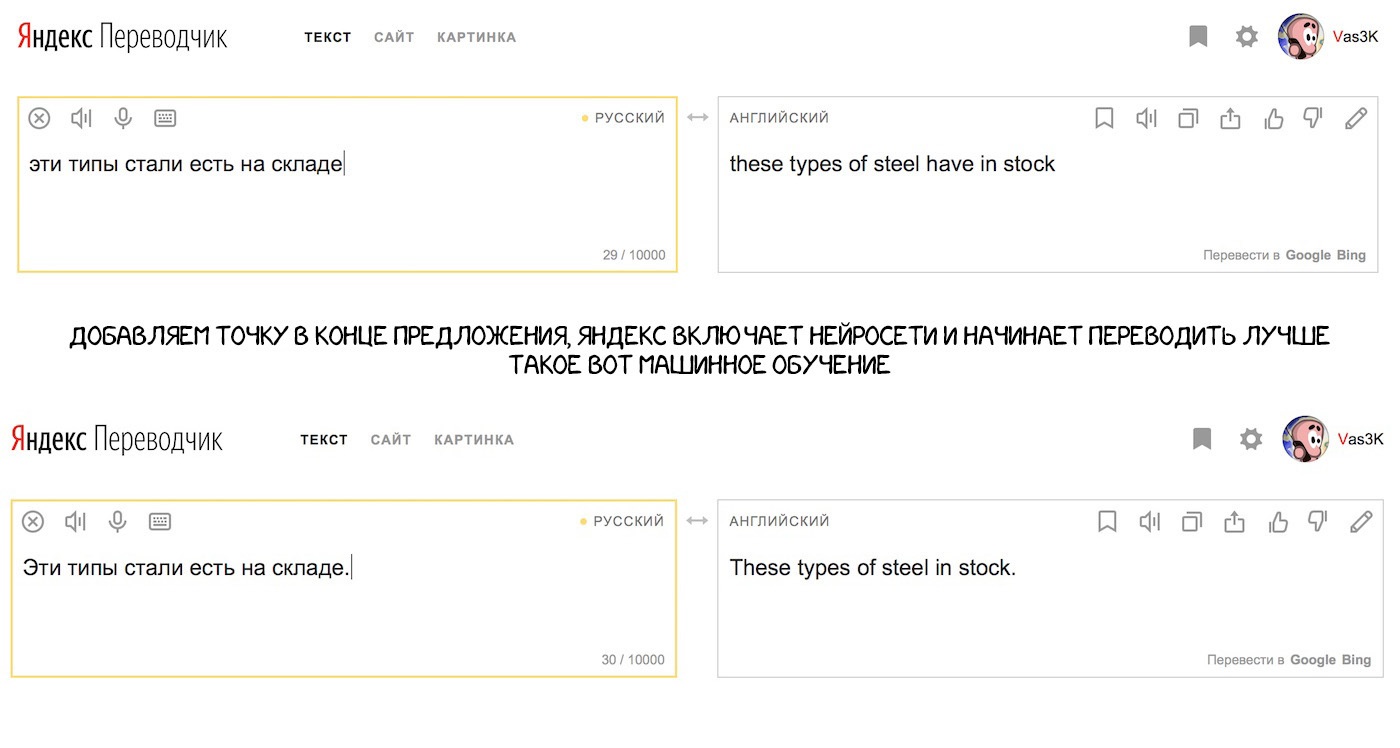
Других подробностей Яндекс нам не рассказывает, отбиваясь нетехническими пресс-релизами. ШТОШ ЛАДНА.
Судя по всему Google тоже использует SMT для перевода слов и коротких словосочетаний. Они не упоминают это в статьях, но это очевидно по разнице между переводами коротких строк и длинных. Также SMT явно используется для показа статистики слова.
Васян, хочешь хурмы отправлю почтой? :)
Хурмовый краудфандинг в действии
ReDetection, да у меня есть, каждый день жру пока сезон. Тут она какая-то хитрая, без косточек, но не всегда сладкая :(
три раза перечитал пример, пока дошло, что типы не есть на склад пришли
OОО, а "на складе" тоже имеет два значения, если уж занудствовать - буквальное положение (сверху) и тот самый in stock
Но ведь сетки это все та же статистика
Макс, +
Что первый, что второй перевод хурмовый, в первом глагол неверный, во втором его вообще нет
Но пишешь ты статью просто песня, читаю и наслаждаюсь
Уже 10 минут пытаюсь добиться, чтобы типы стали типами, всмысле... Блиин
Раньше Гуглопереводчик переводил лучше, чем Яндекс. Но последнее время Яндекс однозначно их уделывает. Хотя я обычно и там, и там проверяю, но вот последние месяцев 8 в 90% случаев выбираю вариант Яндекса
Отписал товарищу про яндес.транслейт может он что расскажет (если интересно)
Всех по прежнему будоражит идея «Вавилонской Рыбки» — синхронного перевода речи на лету. Google делала шаг в этом направлении, когда анонсировала Pixel Buds, но на поверку всё оказалось плохо. Синхронный перевод на лету отличается от обычного, ведь нужно знать места, когда начать переводить, а когда сидеть и слушать. Подходов к решению этой задачи я еще не встречал.
upd: В комментариях отругали, что не вспомнил Skype с переводом на лету. Исправляюсь.
Вот еще одно непаханное поле на мой взгляд: всё обучение по прежнему упирается в ограниченный набор параллельных корпусов с текстами. Хвалёные глубоченные нейросети всё равно обучаются именно на параллельных текстах. Мы не можем обучить нейросеть, не давая ей оригинала. Но человек-то может, начиная с определённого уровня знаний языка, пополнять словарный запас просто от чтения книг или статей, даже не переводя их на свой родной язык.
Если может человек, то и нейросеть, в теории, тоже. Встречал только один прототип, где придумали как заставить обученную одному языку нейросеть бросить на другие тексты, чтобы набралась побольше опыта. Я бы и сам попробовал, но я глупенький. Так что на этом всё.
А я надеялся про феномен монгольского языка в гугл-транслейте что-то вычитать :(
xm02, а что за феномен? Не слышал.
А как же реалтайм перевод от скайпа? https://blogs.skype.com/news/2017/04/06/skype-translator-offers-japanese-10th-real-time-spoken-language/
Хвалёные глубоченные нейросети всё равно обучаются именно на параллельных текстах Not anymore. Прямо вот на этой неделе проходит школа-хакатон по semisupervised machine teanslation (дают мало параллельных текстов и много текстов на каждом из языков отдельно). Тут за последние два года чуваки понаисследовали и получили классные результаты. Более того, в 2017 чуваки научились переводить с одного языка на другой вообще не используя параллельных текстов (О_о). Качетство, конечно, хуже, чем если с параллельными, но, говорят, иногда если обучить Unsupervised на многих данных (~ миллионов) или Supervised на ~100000 пар предложений -- Unsupervised выиграет! Вот тут (https://youtu.be/h59eTySJFKY?t=1h4m7s) где-то с 1:00:00 чувак обзорно рассказывает (остальная часть видоса тоже интересная)
Вастрик, запили \n
thefacetakt, ух ты как. Значит я предугадал, просто не нашел исследований на эту тему. А \n работает, но пока только после перезагрузки страницы :)
xm02, вот в телеге видел одну теорию, но она не сочетается со смыслом статьи, поэтому я уже и сам не знаю как это объяснить. вот линк на ту теорию t.me/linguistique_sur_un_genou/771
https://www.youtube.com/watch?v=P074_t0rIF4 вот про монгольские переводы полайтовее обзорчик, кому лень читать
или например почему в яндекс.переводе есть татарский, а в гугле нет -> кутаклар гугловцы "_"
+1 Леониду с новостью о синхронном переводе в скайпе. писать в блог что гугол сделал шаг и не вспомнить скайп - неприятный фанбоизм. чесслово
двачер, вот для этого у меня и стоят комменты под каждым блоком. Понятия не имел что там у скайпа
Классный обзор, спасибо огромное!
Не совсем перевод, но гугл митс умеет синхронно подсвечивать субтитры. А там (теоретически, хехе) и до перевода недалеко
Очень круто, что появился список источников.
Бесит в самом заголовке заимствование "диплёрнинг". и "гайд" в источниках. Ну неужели нельзя подобрать эквивалент, пусть даже и описательным путем? Мы все же в Росии живем. "Видос" - зачем такие формы? Уже молчу о том, чтогде-то промелькнуло "говно". Ну товарищи, это все-таки статья, претендующая на жанр научно-популярной? Зачем же такой шпанский стиль?
это все-таки статья, претендующая на жанр научно-популярной? Кто вам такое сказал? Это мой блог, а не журнал «огонёк». А про слово «говно» полностью согласен, всего лишь дважды в статье встречается, обычно чаще. Надо исправляться.
Хм....интересно. Википедия: "Блог -интернет-журнал событий, интернет-дневник, онлайн-дневник) — веб-сайт, основное содержимое которого — регулярно добавляемые записи, содержащие текст, изображения или мультимедиа". А здесь ене протсо "текст" - а содержание очень даже тянет на публикацию, пестрит интересными и умными понятиями.
Бертик, ага, такой вот у меня странный формат. Говорим о технологиях в пижонском стиле и «шпанским» языком :)
"кучка стран сорок лет подряд пытались шпионить друг за другом** "кучка" - ед ч., она не ""пытались". Текст совсем не вычитывался, или грамотность в стране уже настолько низко и безвозвратно упала?
Васенька, почитала о тебе на фейсбуке. Молодчинка! Ты такой образованный красавчик, как жаль, что ты в Вильнюсе, а не в Москве!
Потрясает количество людей, которые пришли читать охуеннейший текст, который им подарили вообще запростотак по доброй воле, не пытаясь им ни рекламы впарить, ни трафика с них получить -- и устроили тут книгу жалоб лейтмотивом "а вы должны". Примерно как те пенсионеры, которым владельцы магазинов по доброй воле выдавали продукты, а они потом писали телеги, что мол Путин велел выдавать по две булки, и жалдина-коммерсант дает по одной...
Автору огромнейшее спасибо. Как специалист по NLP и преподаватель оного я в первую очередь восхищен доступностью текста... Всем бы так уметь про сложное рассказывать.
Согласна с Даней стопитьсот, Васик, хочу тебя еще читать, где ты есть, дай ссылки)))
круто.
познавательная минутка ^^
В последнее время Гугл конечно заметно лучше переводит. Интересно, а какие ресурсы (железные) тратятся на это?
Вася, каковы причины создания этого поста? По работе понадобилось, али как?
anonymous, нет, моя работа никак не связана с моими постами. Принципиально. Причина написания в том, что тема показалась подходящей, интересной, нестареющей и люди просили больше писать про NLP.
vas3k, а что за принципы такие? Чтобы отдыхать хоть как-то от работы?
Вэстрик, это восхитительно, спасибо. А что делать, если я хочу переводить с русского на русский? Ну, например, пересказывать текст простыми словами. Или (что важнее) генерировать шутки-хуютки на любые слова.
Спасибо, отличная статья. Пока гугл-транслейт нем-рус всё ещё идёт через английский и часто лепит полную пургу (говорю как краевед) :)
cornholio, как раз пытался вспомнить самые смешные примеры лажи гуглотранслейта (кроме монгольского перевода), но так и не смог. А много-же было. Кинь в меня скрином, если помнишь?
Познавательно, спасибо тебе!
"Кучка стран сорок лет подряд пытались шпионить друг за другом" "Кучка" - единств. число., она не ""пытались". Как же утомляет безграмотность нашего времени (
Кристина, действительно, безграмотность утомляет. Не знать, что такое куки, и просто менять имя в комментах. vas3k, а расскажи, как лог комментов работает?
heavis, по IP автора. Может быть у них просто один офис любителей покряхтеть в интернете :)
И что, heavis, а суть-то та же, хоть меняй ник. хоть нет. Говоря о безграмотности, я вообще-то имею в виду не информационные технологии - вот тут-то мы преуспели за последние годы. И только в этой области, пожалуй. Считаю, что тот, у кого русский язык родной, должен писать корректно, ну или хотя бы вычитать за собой материал, как бы шедеврален он ни был. Это часть общего упадка культуры и образования (опять же, не айти), увы.
Кристина, АХАХА, У ТЕБЯ ВТОРОЕ ПРЕДЛОЖЕНИЕ С МАЛЕНЬКОЙ БУКВЫ БЕЗГРАМОТНАЯ!
А еще непонятно как "кучка стран" могла бы следить друг за другом. ОНА ЖЕ ОДНА ТУТ НА*Й! Только сама за собой следить? Бред.
http://stanbiron.com/images/GoogleTranslatorCapture.png
123
Автору огромнейшее спасибо. Как специалист по NLP и преподаватель оного я в первую очередь восхищен доступностью текста... Всем бы так уметь про сложное рассказывать.
Самая дельная статья, которую я читала за последнее время. Большое спасибо автору! Великолепно структурированный материал и легкая манера письма!
Кристина, действительно знающие русский язык знают явление числительных выраженных существительным, типа дюжина, тьма и т.п. Случай Кучки именно такой, так что идите учить русский язык!..
Вастрик, а на ваш взгляд, на какой срок от решения классической задачи англ-> рус отстоит задача перевода на русский английской речи в исполнении плохо знающего английский язык француза (контаминация грамматическими структурами, ЛДП и своеобразное произношение)? спасибо
Вастрик спасибо!
Как же ты умеешь охренительно понятно, просто, а главное — ещё и задорно рассказывать такие фундаментальные и тяжёлые для понимания вещи. Как-то даже обидно читать под таким трудом мелочные комментарии про ошибки/описки.
Мир и любовь тебе, то что ты делаешь — ценно 💛